 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Risk Curves of signSGD in High-Dimensions: Quantifying Preconditioning and Noise-Compression Effects
Nov 19, 2024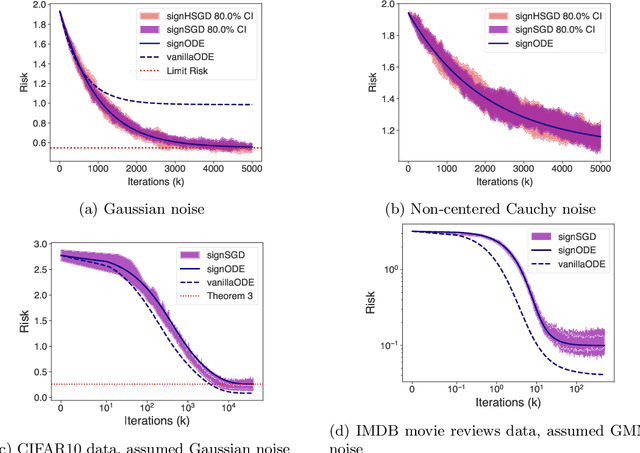
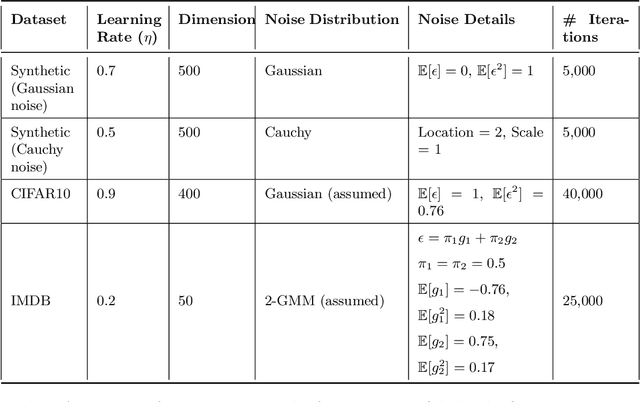
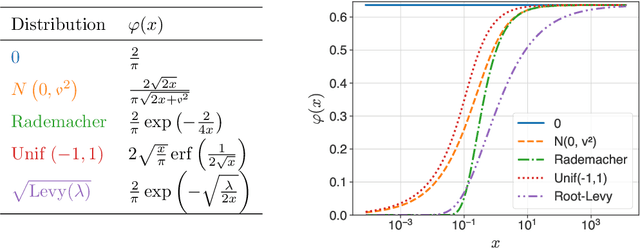
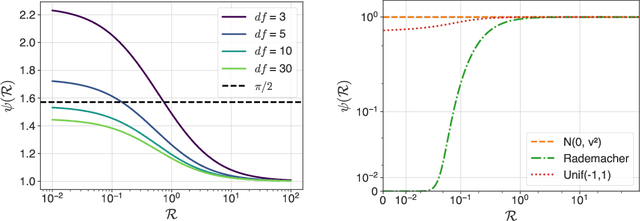
In recent years, signSGD has garnered interest as both a practical optimizer as well as a simple model to understand adaptive optimizers like Adam. Though there is a general consensus that signSGD acts to precondition optimization and reshapes noise, quantitatively understanding these effects in theoretically solvable settings remains difficult. We present an analysis of signSGD in a high dimensional limit, and derive a limiting SDE and ODE to describe the risk. Using this framework we quantify four effects of signSGD: effective learning rate, noise compression, diagonal preconditioning, and gradient noise reshaping. Our analysis is consistent with experimental observations but moves beyond that by quantifying the dependence of these effects on the data and noise distributions. We conclude with a conjecture on how these results might be extended to Adam.
A Clipped Trip: the Dynamics of SGD with Gradient Clipping in High-Dimensions
Jun 17, 2024The success of modern machine learning is due in part to the adaptive optimization methods that have been developed to deal with the difficulties of training large models over complex datasets. One such method is gradient clipping: a practical procedure with limited theoretical underpinnings. In this work, we study clipping in a least squares problem under streaming SGD. We develop a theoretical analysis of the learning dynamics in the limit of large intrinsic dimension-a model and dataset dependent notion of dimensionality. In this limit we find a deterministic equation that describes the evolution of the loss. We show that with Gaussian noise clipping cannot improve SGD performance. Yet, in other noisy settings, clipping can provide benefits with tuning of the clipping threshold. In these cases, clipping biases updates in a way beneficial to training which cannot be recovered by SGD under any schedule. We conclude with a discussion about the links between high-dimensional clipping and neural network training.