 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrade-offs in Top-k Classification Accuracies on Losses for Deep Learning
Jul 30, 2020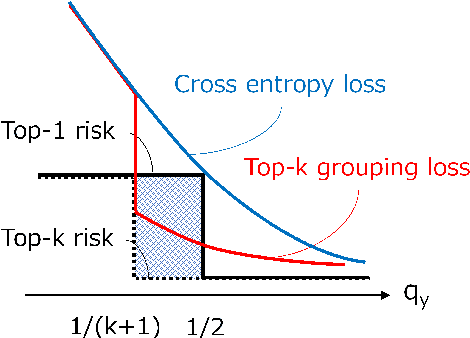
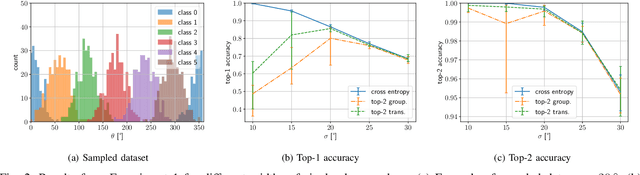
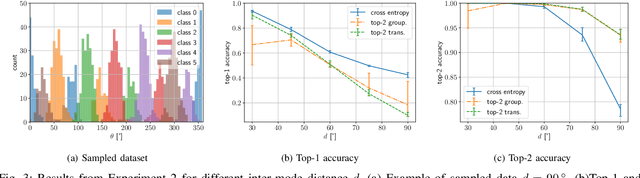
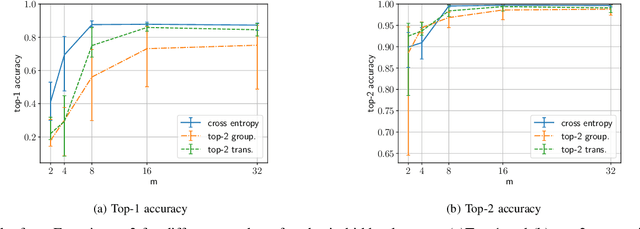
This paper presents an experimental analysis about trade-offs in top-k classification accuracies on losses for deep leaning and proposal of a novel top-k loss. Commonly-used cross entropy (CE) is not guaranteed to optimize top-k prediction without infinite training data and model complexities. The objective is to clarify when CE sacrifices top-k accuracies to optimize top-1 prediction, and to design loss that improve top-k accuracy under such conditions. Our novel loss is basically CE modified by grouping temporal top-k classes as a single class. To obtain a robust decision boundary, we introduce an adaptive transition from normal CE to our loss, and thus call it top-k transition loss. It is demonstrated that CE is not always the best choice to learn top-k prediction in our experiments. First, we explore trade-offs between top-1 and top-k (=2) accuracies on synthetic datasets, and find a failure of CE in optimizing top-k prediction when we have complex data distribution for a given model to represent optimal top-1 prediction. Second, we compare top-k accuracies on CIFAR-100 dataset targeting top-5 prediction in deep learning. While CE performs the best in top-1 accuracy, in top-5 accuracy our loss performs better than CE except using one experimental setup. Moreover, our loss has been found to provide better top-k accuracies compared to CE at k larger than 10. As a result, a ResNet18 model trained with our loss reaches 99 % accuracy with k=25 candidates, which is a smaller candidate number than that of CE by 8.
Rollable Latent Space for Azimuth Invariant SAR Target Recognition
Apr 20, 2018
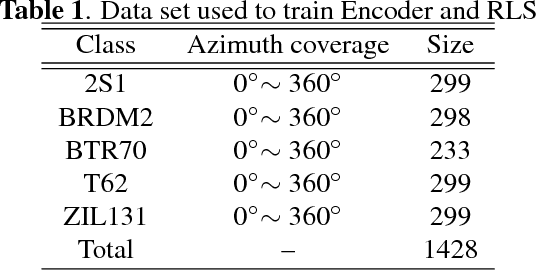
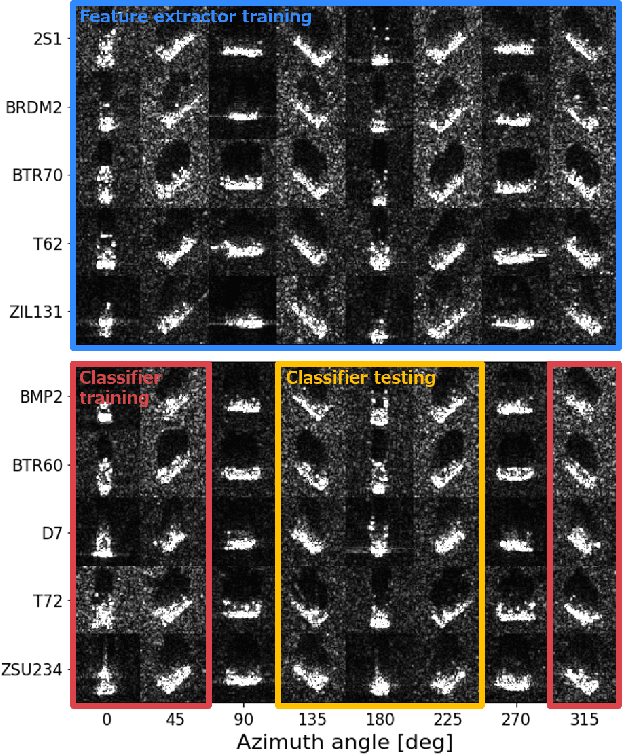
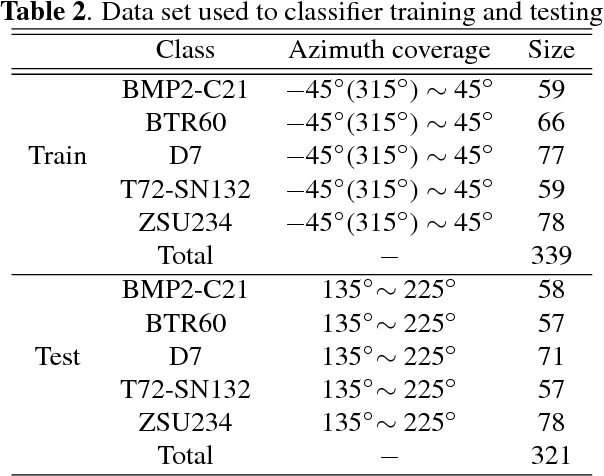
This paper proposes rollable latent space (RLS) for an azimuth invariant synthetic aperture radar (SAR) target recognition. Scarce labeled data and limited viewing direction are critical issues in SAR target recognition.The RLS is a designed space in which rolling of latent features corresponds to 3D rotation of an object. Thus latent features of an arbitrary view can be inferred using those of different views. This characteristic further enables us to augment data from limited viewing in RLS. RLS-based classifiers with and without data augmentation and a conventional classifier trained with target front shots are evaluated over untrained target back shots. Results show that the RLS-based classifier with augmentation improves an accuracy by 30% compared to the conventional classifier.