 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Deep Learning Models for Hostility Detection in Hindi Text
Jan 13, 2021

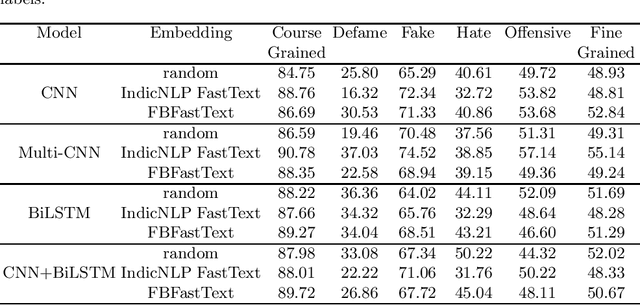

The social media platform is a convenient medium to express personal thoughts and share useful information. It is fast, concise, and has the ability to reach millions. It is an effective place to archive thoughts, share artistic content, receive feedback, promote products, etc. Despite having numerous advantages these platforms have given a boost to hostile posts. Hate speech and derogatory remarks are being posted for personal satisfaction or political gain. The hostile posts can have a bullying effect rendering the entire platform experience hostile. Therefore detection of hostile posts is important to maintain social media hygiene. The problem is more pronounced languages like Hindi which are low in resources. In this work, we present approaches for hostile text detection in the Hindi language. The proposed approaches are evaluated on the Constraint@AAAI 2021 Hindi hostility detection dataset. The dataset consists of hostile and non-hostile texts collected from social media platforms. The hostile posts are further segregated into overlapping classes of fake, offensive, hate, and defamation. We evaluate a host of deep learning approaches based on CNN, LSTM, and BERT for this multi-label classification problem. The pre-trained Hindi fast text word embeddings by IndicNLP and Facebook are used in conjunction with CNN and LSTM models. Two variations of pre-trained multilingual transformer language models mBERT and IndicBERT are used. We show that the performance of BERT based models is best. Moreover, CNN and LSTM models also perform competitively with BERT based models.
Domain Adaptation of NMT models for English-Hindi Machine Translation Task at AdapMT ICON 2020
Dec 23, 2020

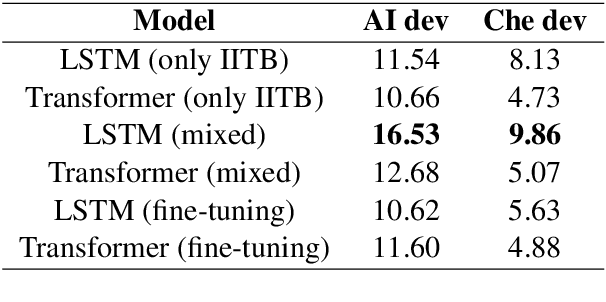

Recent advancements in Neural Machine Translation (NMT) models have proved to produce a state of the art results on machine translation for low resource Indian languages. This paper describes the neural machine translation systems for the English-Hindi language presented in AdapMT Shared Task ICON 2020. The shared task aims to build a translation system for Indian languages in specific domains like Artificial Intelligence (AI) and Chemistry using a small in-domain parallel corpus. We evaluated the effectiveness of two popular NMT models i.e, LSTM, and Transformer architectures for the English-Hindi machine translation task based on BLEU scores. We train these models primarily using the out of domain data and employ simple domain adaptation techniques based on the characteristics of the in-domain dataset. The fine-tuning and mixed-domain data approaches are used for domain adaptation. Our team was ranked first in the chemistry and general domain En-Hi translation task and second in the AI domain En-Hi translation task.