 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASPEN: Spectral-Temporal Fusion for Cross-Subject Brain Decoding
Feb 18, 2026Cross-subject generalization in EEG-based brain-computer interfaces (BCIs) remains challenging due to individual variability in neural signals. We investigate whether spectral representations offer more stable features for cross-subject transfer than temporal waveforms. Through correlation analyses across three EEG paradigms (SSVEP, P300, and Motor Imagery), we find that spectral features exhibit consistently higher cross-subject similarity than temporal signals. Motivated by this observation, we introduce ASPEN, a hybrid architecture that combines spectral and temporal feature streams via multiplicative fusion, requiring cross-modal agreement for features to propagate. Experiments across six benchmark datasets reveal that ASPEN is able to dynamically achieve the optimal spectral-temporal balance depending on the paradigm. ASPEN achieves the best unseen-subject accuracy on three of six datasets and competitive performance on others, demonstrating that multiplicative multimodal fusion enables effective cross-subject generalization.
Decoding EEG Speech Perception with Transformers and VAE-based Data Augmentation
Jan 08, 2025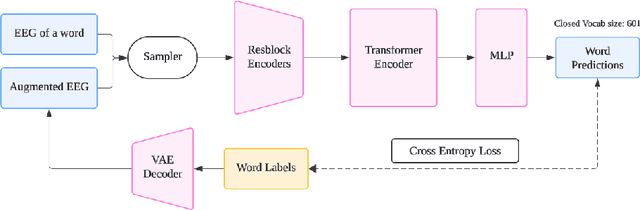
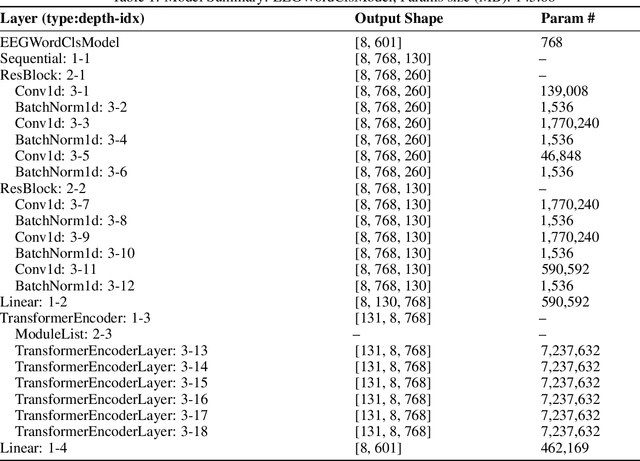
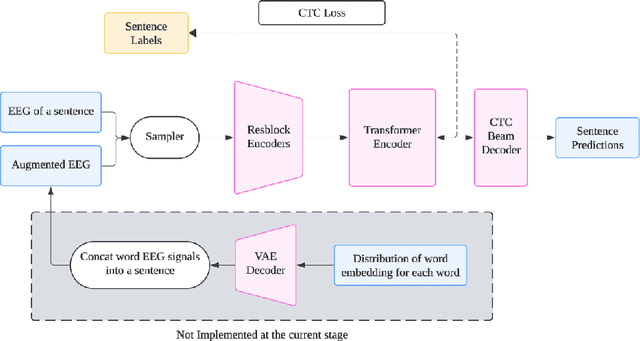
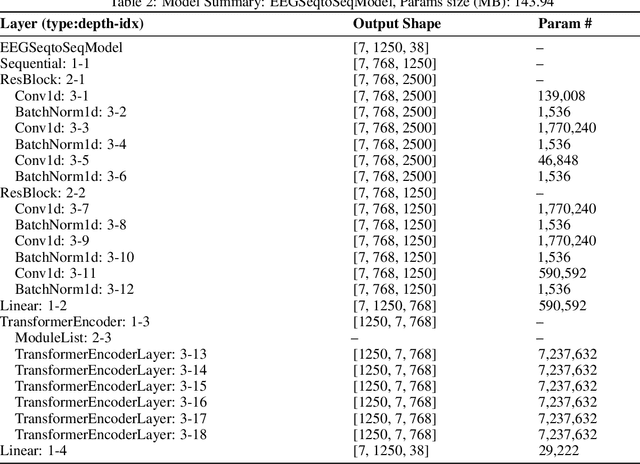
Decoding speech from non-invasive brain signals, such as electroencephalography (EEG), has the potential to advance brain-computer interfaces (BCIs), with applications in silent communication and assistive technologies for individuals with speech impairments. However, EEG-based speech decoding faces major challenges, such as noisy data, limited datasets, and poor performance on complex tasks like speech perception. This study attempts to address these challenges by employing variational autoencoders (VAEs) for EEG data augmentation to improve data quality and applying a state-of-the-art (SOTA) sequence-to-sequence deep learning architecture, originally successful in electromyography (EMG) tasks, to EEG-based speech decoding. Additionally, we adapt this architecture for word classification tasks. Using the Brennan dataset, which contains EEG recordings of subjects listening to narrated speech, we preprocess the data and evaluate both classification and sequence-to-sequence models for EEG-to-words/sentences tasks. Our experiments show that VAEs have the potential to reconstruct artificial EEG data for augmentation. Meanwhile, our sequence-to-sequence model achieves more promising performance in generating sentences compared to our classification model, though both remain challenging tasks. These findings lay the groundwork for future research on EEG speech perception decoding, with possible extensions to speech production tasks such as silent or imagined speech.
Improving SSVEP BCI Spellers With Data Augmentation and Language Models
Dec 28, 2024

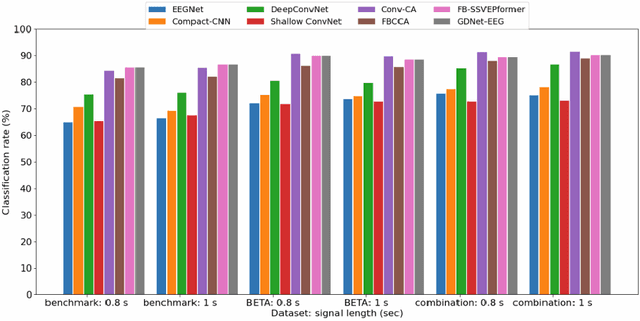
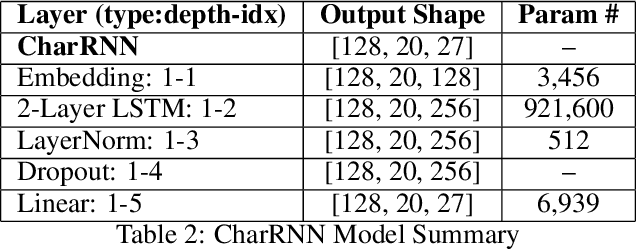
Steady-State Visual Evoked Potential (SSVEP) spellers are a promising communication tool for individuals with disabilities. This Brain-Computer Interface utilizes scalp potential data from (electroencephalography) EEG electrodes on a subject's head to decode specific letters or arbitrary targets the subject is looking at on a screen. However, deep neural networks for SSVEP spellers often suffer from low accuracy and poor generalizability to unseen subjects, largely due to the high variability in EEG data. In this study, we propose a hybrid approach combining data augmentation and language modeling to enhance the performance of SSVEP spellers. Using the Benchmark dataset from Tsinghua University, we explore various data augmentation techniques, including frequency masking, time masking, and noise injection, to improve the robustness of deep learning models. Additionally, we integrate a language model (CharRNN) with EEGNet to incorporate linguistic context, significantly enhancing word-level decoding accuracy. Our results demonstrate accuracy improvements of up to 2.9 percent over the baseline, with time masking and language modeling showing the most promise. This work paves the way for more accurate and generalizable SSVEP speller systems, offering improved communication solutions for individuals with disabilities.