 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Quality and Stability of a Streaming End-to-End On-Device Speech Recognizer
Jun 02, 2020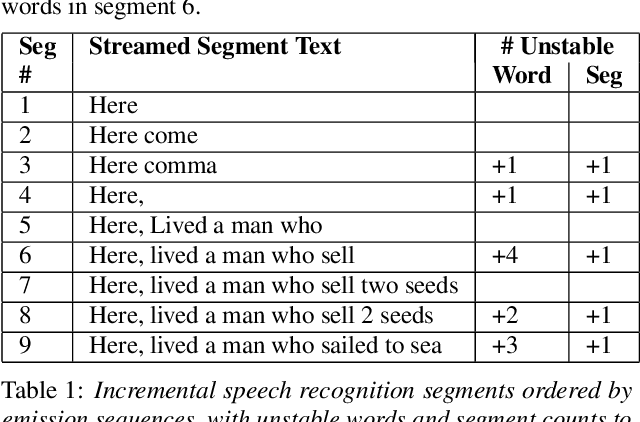
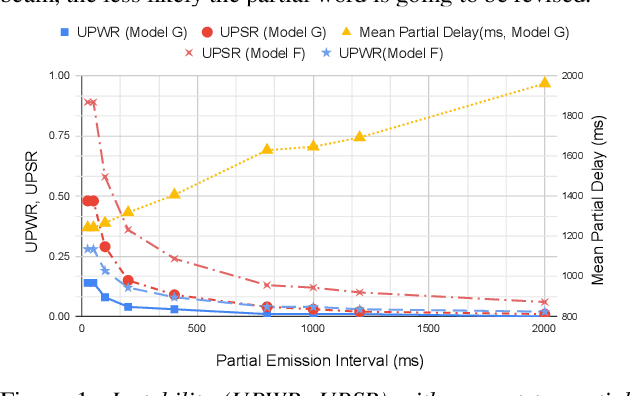
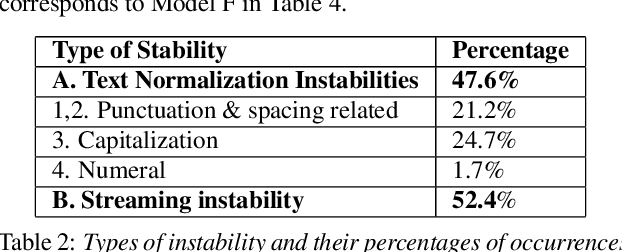
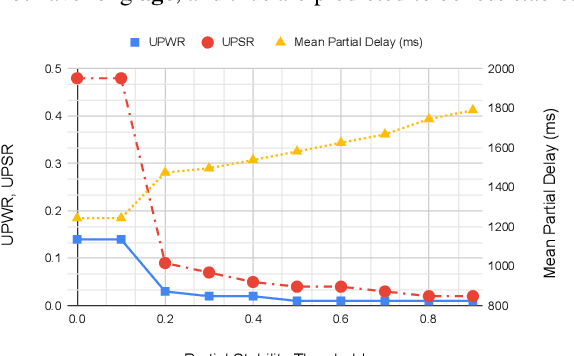
The demand for fast and accurate incremental speech recognition increases as the applications of automatic speech recognition (ASR) proliferate. Incremental speech recognizers output chunks of partially recognized words while the user is still talking. Partial results can be revised before the ASR finalizes its hypothesis, causing instability issues. We analyze the quality and stability of on-device streaming end-to-end (E2E) ASR models. We first introduce a novel set of metrics that quantify the instability at word and segment levels. We study the impact of several model training techniques that improve E2E model qualities but degrade model stability. We categorize the causes of instability and explore various solutions to mitigate them in a streaming E2E ASR system. Index Terms: ASR, stability, end-to-end, text normalization,on-device, RNN-T