 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closed-Form Approximation to the Conjugate Prior of the Dirichlet and Beta Distributions
Jul 07, 2021
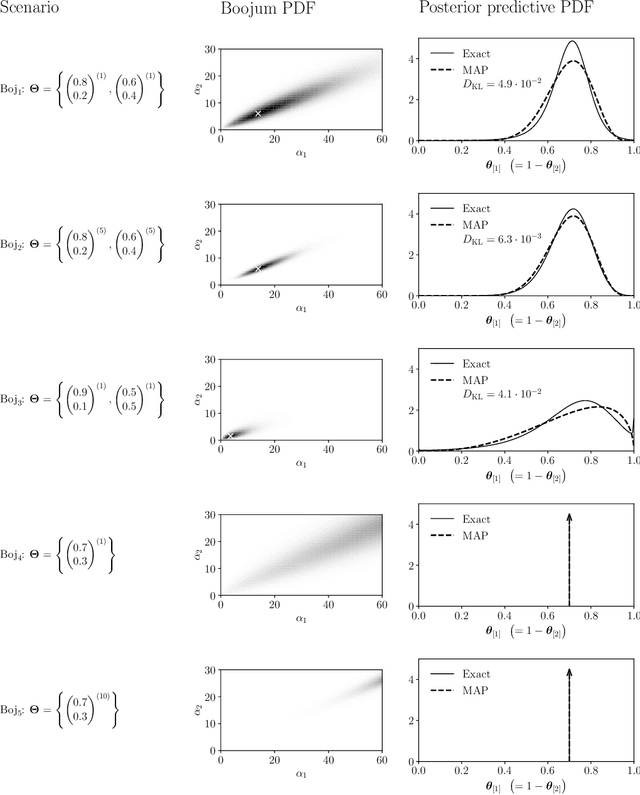
We derive the conjugate prior of the Dirichlet and beta distributions and explore it with numerical examples to gain an intuitive understanding of the distribution itself, its hyperparameters, and conditions concerning its convergence. Due to the prior's intractability, we proceed to define and analyze a closed-form approximation. Finally, we provide an algorithm implementing this approximation that enables fully tractable Bayesian conjugate treatment of Dirichlet and beta likelihoods without the need for Monte Carlo simulations.
Adaptive Bayesian Reticulum
Jan 29, 2020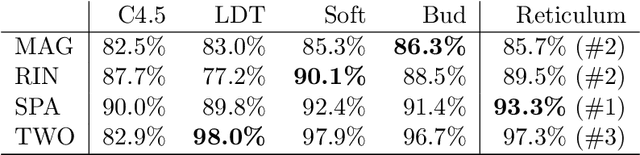
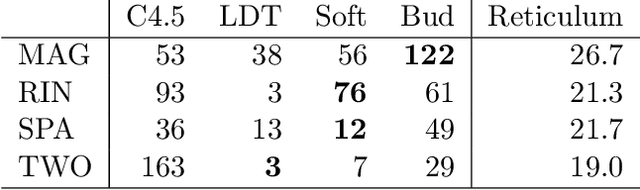
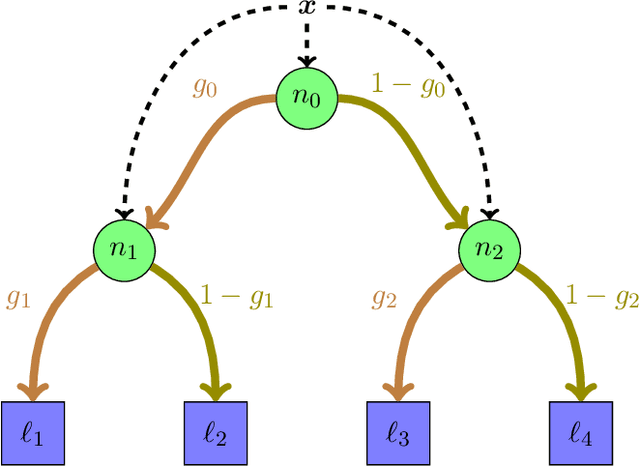
Neural Networks and Random Forests: two popular techniques for supervised learning that are seemingly disconnected in their formulation and optimization method, have recently been linked in a single construct. The connection pivots on assembling an artificial Neural Network with nodes that allow for a gate-like function to mimic a tree split, optimized using the standard approach of recursively applying the chain rule to update its parameters. Yet two main challenges have impeded wide use of this hybrid approach: \emph{(a)} the inability of global gradient descent techniques to optimize hierarchical parameters (as introduced by the gate function); and \emph{(b)} the construction of the tree structure, which has relied on standard decision tree algorithms to learn the network topology or incrementally (and heuristically) searching the space at random. We propose a probabilistic construct that exploits the idea of a node's \emph{unexplained potential} (the total error channeled through the node) in order to decide where to expand further, mimicking the standard tree construction in a Neural Network setting, alongside a modified gradient descent that first locally optimizes an expanded node before a global optimization. The probabilistic approach allows us to evaluate each new split as a ratio of likelihoods that balance the statistical improvement in explaining the evidence against the additional model complexity --- thus providing a natural stopping condition. The result is a novel classification and regression technique that leverages the strength of both: a tree-structure that grows naturally and is simple to interpret with the plasticity of Neural Networks that allow for soft margins and slanted boundaries.