 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning for Meaningful Human Control in Military Human-Machine Teams
May 12, 2023



We propose methods for analysis, design, and evaluation of Meaningful Human Control (MHC) for defense technologies from the perspective of military human-machine teaming (HMT). Our approach is based on three principles. Firstly, MHC should be regarded as a core objective that guides all phases of analysis, design and evaluation. Secondly, MHC affects all parts of the socio-technical system, including humans, machines, AI, interactions, and context. Lastly, MHC should be viewed as a property that spans longer periods of time, encompassing both prior and realtime control by multiple actors. To describe macrolevel design options for achieving MHC, we propose various Team Design Patterns. Furthermore, we present a case study, where we applied some of these methods to envision HMT, involving robots and soldiers in a search and rescue task in a military context.
Contrastive Explanations for Reinforcement Learning in terms of Expected Consequences
Jul 23, 2018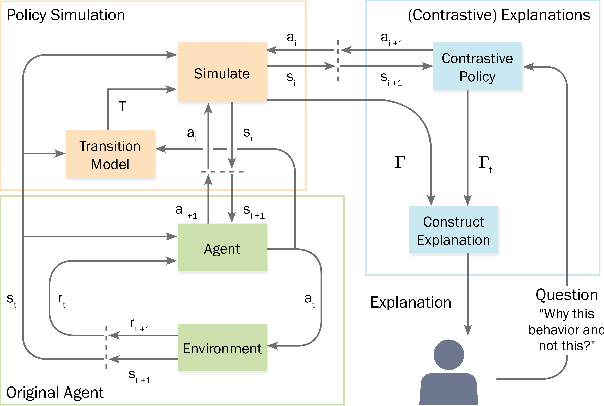

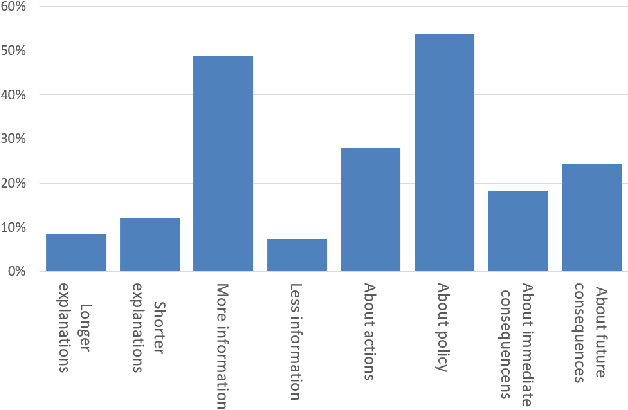
Machine Learning models become increasingly proficient in complex tasks. However, even for experts in the field, it can be difficult to understand what the model learned. This hampers trust and acceptance, and it obstructs the possibility to correct the model. There is therefore a need for transparency of machine learning models. The development of transparent classification models has received much attention, but there are few developments for achieving transparent Reinforcement Learning (RL) models. In this study we propose a method that enables a RL agent to explain its behavior in terms of the expected consequences of state transitions and outcomes. First, we define a translation of states and actions to a description that is easier to understand for human users. Second, we developed a procedure that enables the agent to obtain the consequences of a single action, as well as its entire policy. The method calculates contrasts between the consequences of a policy derived from a user query, and of the learned policy of the agent. Third, a format for generating explanations was constructed. A pilot survey study was conducted to explore preferences of users for different explanation properties. Results indicate that human users tend to favor explanations about policy rather than about single actions.
* XAI workshop on the IJCAI conference 2018, Stockholm, Sweden