 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Skeleton-based Action Recognitionwith Robust Spatial and Temporal Features
Aug 01, 2020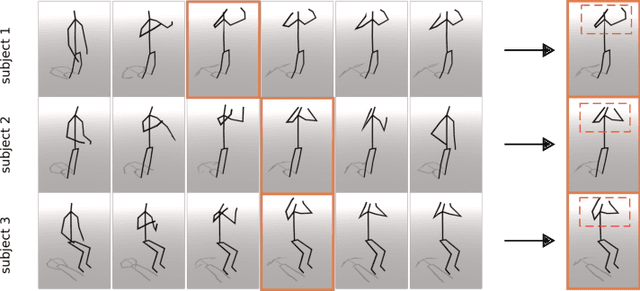
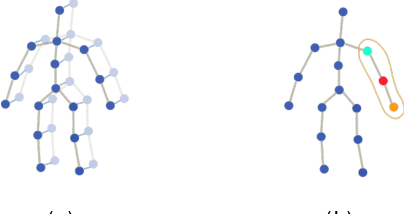
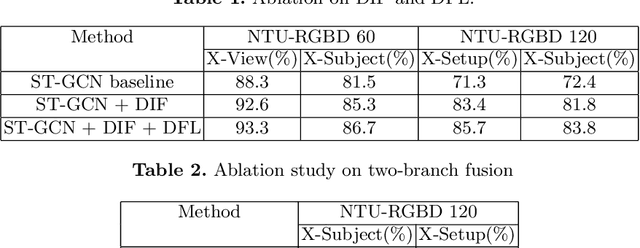
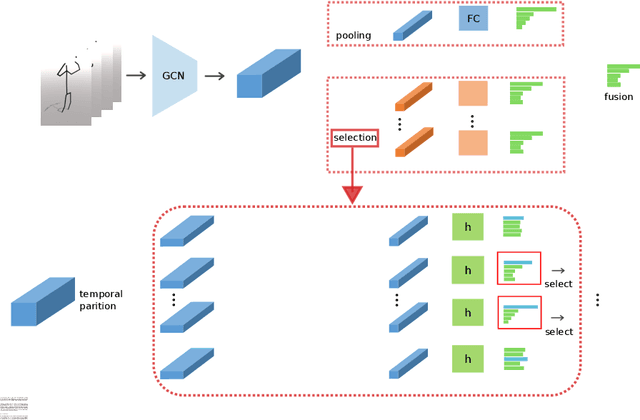
Recently skeleton-based action recognition has made signif-icant progresses in the computer vision community. Most state-of-the-art algorithms are based on Graph Convolutional Networks (GCN), andtarget at improving the network structure of the backbone GCN lay-ers. In this paper, we propose a novel mechanism to learn more robustdiscriminative features in space and time. More specifically, we add aDiscriminative Feature Learning (DFL) branch to the last layers of thenetwork to extract discriminative spatial and temporal features to helpregularize the learning. We also formally advocate the use of Direction-Invariant Features (DIF) as input to the neural networks. We show thataction recognition accuracy can be improved when these robust featuresare learned and used. We compare our results with those of ST-GCNand related methods on four datasets: NTU-RGBD60, NTU-RGBD120,SYSU 3DHOI and Skeleton-Kinetics.