 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical and Experimental Perspectives on Big Data in Recommendation Systems: A Comprehensive Survey
Feb 01, 2024



This survey paper provides a comprehensive analysis of big data algorithms in recommendation systems, addressing the lack of depth and precision in existing literature. It proposes a two-pronged approach: a thorough analysis of current algorithms and a novel, hierarchical taxonomy for precise categorization. The taxonomy is based on a tri-level hierarchy, starting with the methodology category and narrowing down to specific techniques. Such a framework allows for a structured and comprehensive classification of algorithms, assisting researchers in understanding the interrelationships among diverse algorithms and techniques. Covering a wide range of algorithms, this taxonomy first categorizes algorithms into four main analysis types: User and Item Similarity-Based Methods, Hybrid and Combined Approaches, Deep Learning and Algorithmic Methods, and Mathematical Modeling Methods, with further subdivisions into sub-categories and techniques. The paper incorporates both empirical and experimental evaluations to differentiate between the techniques. The empirical evaluation ranks the techniques based on four criteria. The experimental assessments rank the algorithms that belong to the same category, sub-category, technique, and sub-technique. Also, the paper illuminates the future prospects of big data techniques in recommendation systems, underscoring potential advancements and opportunities for further research in this field
Techniques to Detect Crime Leaders within a Criminal Network: A Survey, Experimental, and Comparative Evaluations
Jan 26, 2024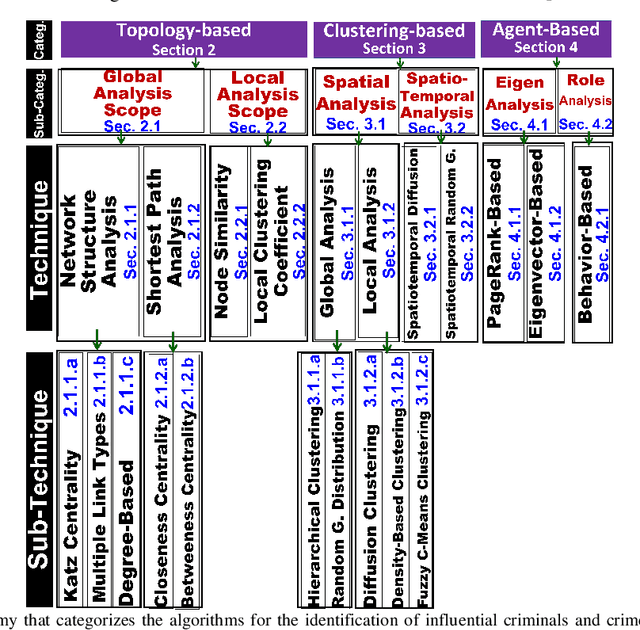
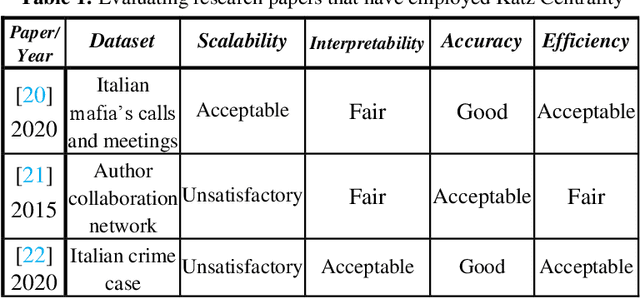
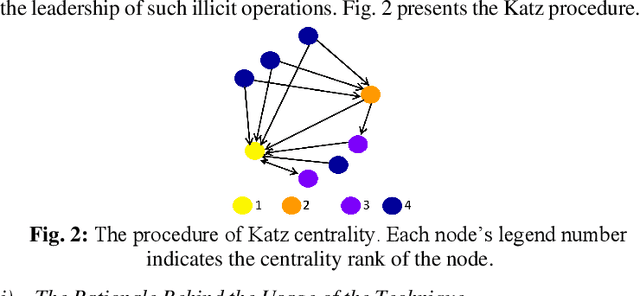
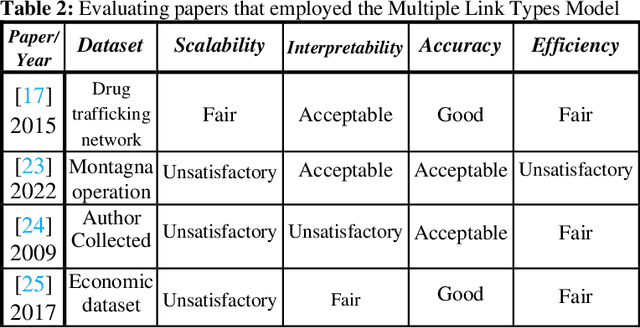
This survey paper offers a thorough analysis of techniques and algorithms used in the identification of crime leaders within criminal networks. For each technique, the paper examines its effectiveness, limitations, potential for improvement, and future prospects. The main challenge faced by existing survey papers focusing on algorithms for identifying crime leaders and predicting crimes is effectively categorizing these algorithms. To address this limitation, this paper proposes a new methodological taxonomy that hierarchically classifies algorithms into more detailed categories and specific techniques. The paper includes empirical and experimental evaluations to rank the different techniques. The combination of the methodological taxonomy, empirical evaluations, and experimental comparisons allows for a nuanced and comprehensive understanding of the techniques and algorithms for identifying crime leaders, assisting researchers in making informed decisions. Moreover, the paper offers valuable insights into the future prospects of techniques for identifying crime leaders, emphasizing potential advancements and opportunities for further research. Here's an overview of our empirical analysis findings and experimental insights, along with the solution we've devised: (1) PageRank and Eigenvector centrality are reliable for mapping network connections, (2) Katz Centrality can effectively identify influential criminals through indirect links, stressing their significance in criminal networks, (3) current models fail to account for the specific impacts of criminal influence levels, the importance of socio-economic context, and the dynamic nature of criminal networks and hierarchies, and (4) we propose enhancements, such as incorporating temporal dynamics and sentiment analysis to reflect the fluidity of criminal activities and relationships, which could improve the detection of key criminals .
Text Classification: A Review, Empirical, and Experimental Evaluation
Jan 11, 2024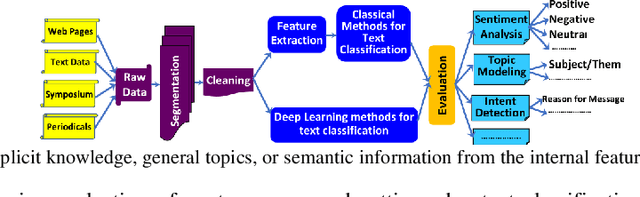



The explosive and widespread growth of data necessitates the use of text classification to extract crucial information from vast amounts of data. Consequently, there has been a surge of research in both classical and deep learning text classification methods. Despite the numerous methods proposed in the literature, there is still a pressing need for a comprehensive and up-to-date survey. Existing survey papers categorize algorithms for text classification into broad classes, which can lead to the misclassification of unrelated algorithms and incorrect assessments of their qualities and behaviors using the same metrics. To address these limitations, our paper introduces a novel methodological taxonomy that classifies algorithms hierarchically into fine-grained classes and specific techniques. The taxonomy includes methodology categories, methodology techniques, and methodology sub-techniques. Our study is the first survey to utilize this methodological taxonomy for classifying algorithms for text classification. Furthermore, our study also conducts empirical evaluation and experimental comparisons and rankings of different algorithms that employ the same specific sub-technique, different sub-techniques within the same technique, different techniques within the same category, and categories
Machine Learning Techniques for Identifying the Defective Patterns in Semiconductor Wafer Maps: A Survey, Empirical, and Experimental Evaluations
Oct 16, 2023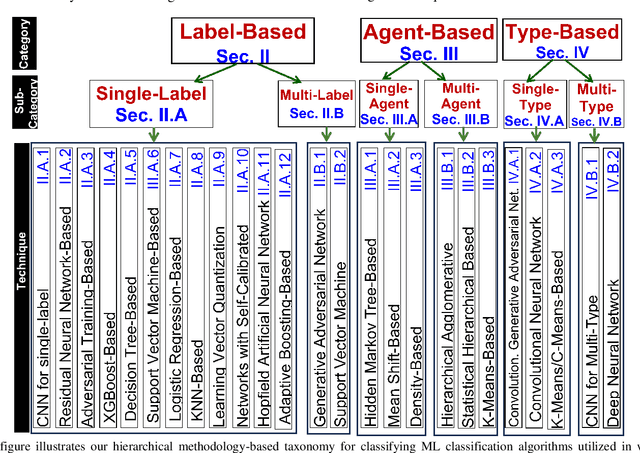

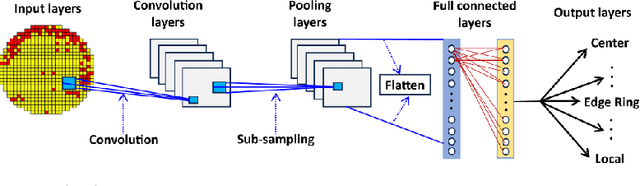
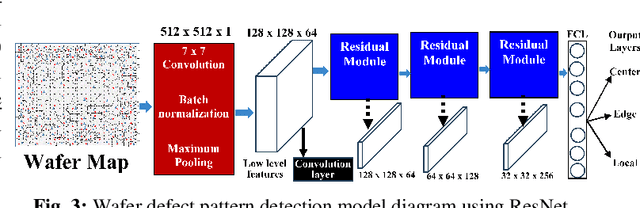
This survey paper offers a comprehensive review of methodologies utilizing machine learning (ML) techniques for identifying wafer defects in semiconductor manufacturing. Despite the growing body of research demonstrating the effectiveness of ML in wafer defect identification, there is a noticeable absence of comprehensive reviews on this subject. This survey attempts to fill this void by amalgamating available literature and providing an in-depth analysis of the advantages, limitations, and potential applications of various ML algorithms in the realm of wafer defect detection. An innovative taxonomy of methodologies that we present provides a detailed classification of algorithms into more refined categories and techniques. This taxonomy follows a four-tier structure, starting from broad methodology categories and ending with specific sub-techniques. It aids researchers in comprehending the complex relationships between different algorithms and their techniques. We employ a rigorous empirical and experimental evaluation to rank these varying techniques. For the empirical evaluation, we assess techniques based on a set of four criteria. The experimental evaluation ranks the algorithms employing the same sub-techniques, techniques, sub-categories, and categories. This integration of a multi-layered taxonomy, empirical evaluations, and comparative experiments provides a detailed and holistic understanding of ML techniques and algorithms for identifying wafer defects. This approach guides researchers towards making more informed decisions in their work. Additionally, the paper illuminates the future prospects of ML techniques for wafer defect identification, underscoring potential advancements and opportunities for further research in this field