 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccessible Instruction-Following Agent
May 08, 2023Humans can collaborate and complete tasks based on visual signals and instruction from the environment. Training such a robot is difficult especially due to the understanding of the instruction and the complicated environment. Previous instruction-following agents are biased to English-centric corpus, making it unrealizable to be applied to users that use multiple languages or even low-resource languages. Nevertheless, the instruction-following agents are pre-trained in a mode that assumes the user can observe the environment, which limits its accessibility. In this work, we're trying to generalize the success of instruction-following agents to non-English languages with little corpus resources, and improve its intractability and accessibility. We introduce UVLN (Universal Vision-Language Navigation), a novel machine-translation instructional augmented framework for cross-lingual vision-language navigation, with a novel composition of state-of-the-art large language model (GPT3) with the image caption model (BLIP). We first collect a multilanguage vision-language navigation dataset via machine translation. Then we extend the standard VLN training objectives to a multilingual setting via a cross-lingual language encoder. The alignment between different languages is captured through a shared vision and action context via a cross-modal transformer, which encodes the inputs of language instruction, visual observation, and action decision sequences. To improve the intractability, we connect our agent with the large language model that informs the situation and current state to the user and also explains the action decisions. Experiments over Room Across Room Dataset prove the effectiveness of our approach. And the qualitative results show the promising intractability and accessibility of our instruction-following agent.
Flexible and Structured Knowledge Grounded Question Answering
Oct 11, 2022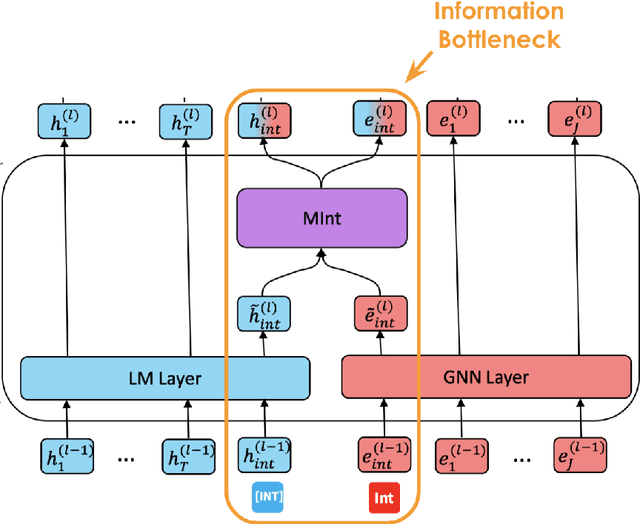

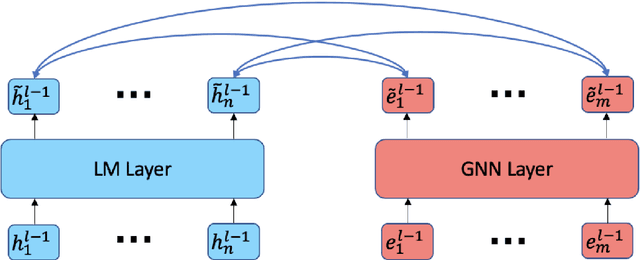

Can language models (LM) ground question-answering (QA) tasks in the knowledge base via inherent relational reasoning ability? While previous models that use only LMs have seen some success on many QA tasks, more recent methods include knowledge graphs (KG) to complement LMs with their more logic-driven implicit knowledge. However, effectively extracting information from structured data, like KGs, empowers LMs to remain an open question, and current models rely on graph techniques to extract knowledge. In this paper, we propose to solely leverage the LMs to combine the language and knowledge for knowledge based question-answering with flexibility, breadth of coverage and structured reasoning. Specifically, we devise a knowledge construction method that retrieves the relevant context with a dynamic hop, which expresses more comprehensivenes than traditional GNN-based techniques. And we devise a deep fusion mechanism to further bridge the information exchanging bottleneck between the language and the knowledge. Extensive experiments show that our model consistently demonstrates its state-of-the-art performance over CommensenseQA benchmark, showcasing the possibility to leverage LMs solely to robustly ground QA into the knowledge base.