 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermutation Learning with Only N Parameters: From SoftSort to Self-Organizing Gaussians
Mar 17, 2025Sorting and permutation learning are key concepts in optimization and machine learning, especially when organizing high-dimensional data into meaningful spatial layouts. The Gumbel-Sinkhorn method, while effective, requires N*N parameters to determine a full permutation matrix, making it computationally expensive for large datasets. Low-rank matrix factorization approximations reduce memory requirements to 2MN (with M << N), but they still struggle with very large problems. SoftSort, by providing a continuous relaxation of the argsort operator, allows differentiable 1D sorting, but it faces challenges with multidimensional data and complex permutations. In this paper, we present a novel method for learning permutations using only N parameters, which dramatically reduces storage costs. Our approach builds on SoftSort, but extends it by iteratively shuffling the N indices of the elements to be sorted through a separable learning process. This modification significantly improves sorting quality, especially for multidimensional data and complex optimization criteria, and outperforms pure SoftSort. Our method offers improved memory efficiency and scalability compared to existing approaches, while maintaining high-quality permutation learning. Its dramatically reduced memory requirements make it particularly well-suited for large-scale optimization tasks, such as "Self-Organizing Gaussians", where efficient and scalable permutation learning is critical.
Creating Sorted Grid Layouts with Gradient-based Optimization
Mar 04, 2025



Visually sorted grid layouts provide an efficient method for organizing high-dimensional vectors in two-dimensional space by aligning spatial proximity with similarity relationships. This approach facilitates the effective sorting of diverse elements ranging from data points to images, and enables the simultaneous visualization of a significant number of elements. However, sorting data on two-dimensional grids is a challenge due to its high complexity. Even for a small 8-by-8 grid with 64 elements, the number of possible arrangements exceeds $1.3 \cdot 10^{89}$ - more than the number of atoms in the universe - making brute-force solutions impractical. Although various methods have been proposed to address the challenge of determining sorted grid layouts, none have investigated the potential of gradient-based optimization. In this paper, we present a novel method for grid-based sorting that exploits gradient optimization for the first time. We introduce a novel loss function that balances two opposing goals: ensuring the generation of a "valid" permutation matrix, and optimizing the arrangement on the grid to reflect the similarity between vectors, inspired by metrics that assess the quality of sorted grids. While learning-based approaches are inherently computationally complex, our method shows promising results in generating sorted grid layouts with superior sorting quality compared to existing techniques.
Optimizing CLIP Models for Image Retrieval with Maintained Joint-Embedding Alignment
Sep 03, 2024Contrastive Language and Image Pairing (CLIP), a transformative method in multimedia retrieval, typically trains two neural networks concurrently to generate joint embeddings for text and image pairs. However, when applied directly, these models often struggle to differentiate between visually distinct images that have similar captions, resulting in suboptimal performance for image-based similarity searches. This paper addresses the challenge of optimizing CLIP models for various image-based similarity search scenarios, while maintaining their effectiveness in text-based search tasks such as text-to-image retrieval and zero-shot classification. We propose and evaluate two novel methods aimed at refining the retrieval capabilities of CLIP without compromising the alignment between text and image embeddings. The first method involves a sequential fine-tuning process: initially optimizing the image encoder for more precise image retrieval and subsequently realigning the text encoder to these optimized image embeddings. The second approach integrates pseudo-captions during the retrieval-optimization phase to foster direct alignment within the embedding space. Through comprehensive experiments, we demonstrate that these methods enhance CLIP's performance on various benchmarks, including image retrieval, k-NN classification, and zero-shot text-based classification, while maintaining robustness in text-to-image retrieval. Our optimized models permit maintaining a single embedding per image, significantly simplifying the infrastructure needed for large-scale multi-modal similarity search systems.
Fast Approximate Nearest Neighbor Search with a Dynamic Exploration Graph using Continuous Refinement
Jul 21, 2023For approximate nearest neighbor search, graph-based algorithms have shown to offer the best trade-off between accuracy and search time. We propose the Dynamic Exploration Graph (DEG) which significantly outperforms existing algorithms in terms of search and exploration efficiency by combining two new ideas: First, a single undirected even regular graph is incrementally built by partially replacing existing edges to integrate new vertices and to update old neighborhoods at the same time. Secondly, an edge optimization algorithm is used to continuously improve the quality of the graph. Combining this ongoing refinement with the graph construction process leads to a well-organized graph structure at all times, resulting in: (1) increased search efficiency, (2) predictable index size, (3) guaranteed connectivity and therefore reachability of all vertices, and (4) a dynamic graph structure. In addition we investigate how well existing graph-based search systems can handle indexed queries where the seed vertex of a search is the query itself. Such exploration tasks, despite their good starting point, are not necessarily easy. High efficiency in approximate nearest neighbor search (ANNS) does not automatically imply good performance in exploratory search. Extensive experiments show that our new Dynamic Exploration Graph outperforms existing algorithms significantly for indexed and unindexed queries.
Improved Evaluation and Generation of Grid Layouts using Distance Preservation Quality and Linear Assignment Sorting
May 11, 2022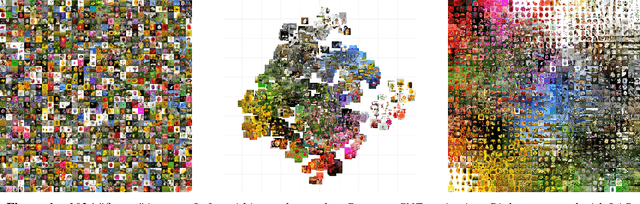
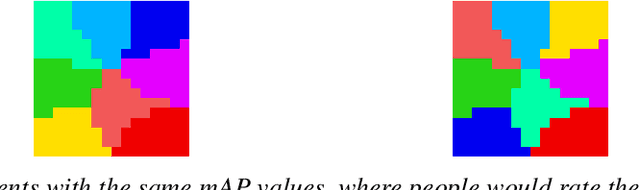

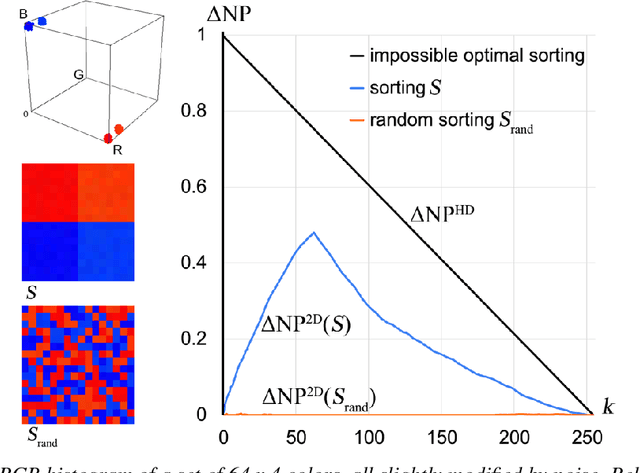
Images sorted by similarity enables more images to be viewed simultaneously, and can be very useful for stock photo agencies or e-commerce applications. Visually sorted grid layouts attempt to arrange images so that their proximity on the grid corresponds as closely as possible to their similarity. Various metrics exist for evaluating such arrangements, but there is low experimental evidence on correlation between human perceived quality and metric value. We propose Distance Preservation Quality (DPQ) as a new metric to evaluate the quality of an arrangement. Extensive user testing revealed stronger correlation of DPQ with user-perceived quality and performance in image retrieval tasks compared to other metrics. In addition, we introduce Fast Linear Assignment Sorting (FLAS) as a new algorithm for creating visually sorted grid layouts. FLAS achieves very good sorting qualities while improving run time and computational resources.
PicArrange -- Visually Sort, Search, and Explore Private Images on a Mac Computer
Nov 26, 2021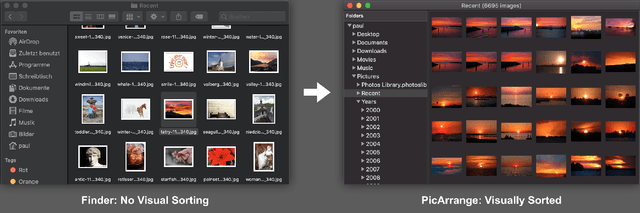
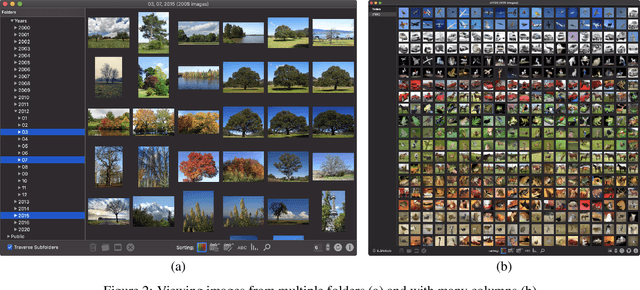
The native macOS application PicArrange integrates state-of-the-art image sorting and similarity search to enable users to get a better overview of their images. Many file and image management features have been added to make it a tool that addresses a full image management workflow. A modification of the Self Sorting Map algorithm enables a list-like image arrangement without loosing the visual sorting. Efficient calculation and storage of visual features as well as the use of many macOS APIs result in an application that is fluid to use.
GPR1200: A Benchmark for General-Purpose Content-Based Image Retrieval
Nov 25, 2021
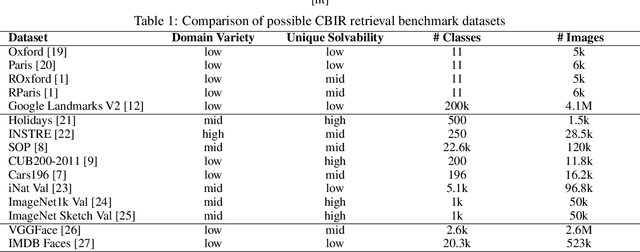

Even though it has extensively been shown that retrieval specific training of deep neural networks is beneficial for nearest neighbor image search quality, most of these models are trained and tested in the domain of landmarks images. However, some applications use images from various other domains and therefore need a network with good generalization properties - a general-purpose CBIR model. To the best of our knowledge, no testing protocol has so far been introduced to benchmark models with respect to general image retrieval quality. After analyzing popular image retrieval test sets we decided to manually curate GPR1200, an easy to use and accessible but challenging benchmark dataset with a broad range of image categories. This benchmark is subsequently used to evaluate various pretrained models of different architectures on their generalization qualities. We show that large-scale pretraining significantly improves retrieval performance and present experiments on how to further increase these properties by appropriate fine-tuning. With these promising results, we hope to increase interest in the research topic of general-purpose CBIR.
Deep Aggregation of Regional Convolutional Activations for Content Based Image Retrieval
Sep 24, 2019

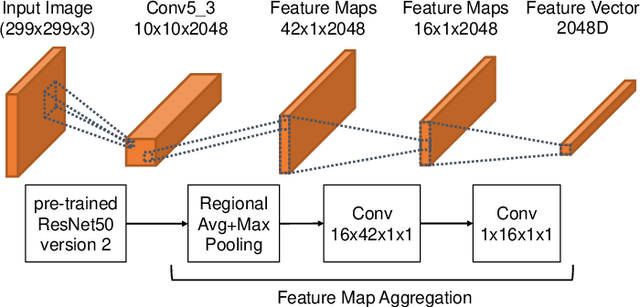
One of the key challenges of deep learning based image retrieval remains in aggregating convolutional activations into one highly representative feature vector. Ideally, this descriptor should encode semantic, spatial and low level information. Even though off-the-shelf pre-trained neural networks can already produce good representations in combination with aggregation methods, appropriate fine tuning for the task of image retrieval has shown to significantly boost retrieval performance. In this paper, we present a simple yet effective supervised aggregation method built on top of existing regional pooling approaches. In addition to the maximum activation of a given region, we calculate regional average activations of extracted feature maps. Subsequently, weights for each of the pooled feature vectors are learned to perform a weighted aggregation to a single feature vector. Furthermore, we apply our newly proposed NRA loss function for deep metric learning to fine tune the backbone neural network and to learn the aggregation weights. Our method achieves state-of-the-art results for the INRIA Holidays data set and competitive results for the Oxford Buildings and Paris data sets while reducing the training time significantly.
Deep Metric Learning using Similarities from Nonlinear Rank Approximations
Sep 24, 2019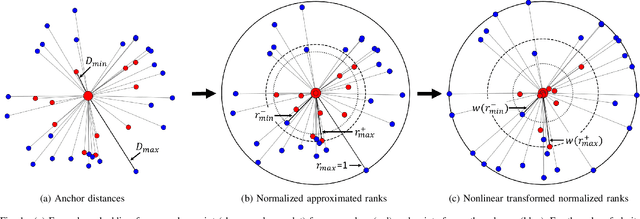
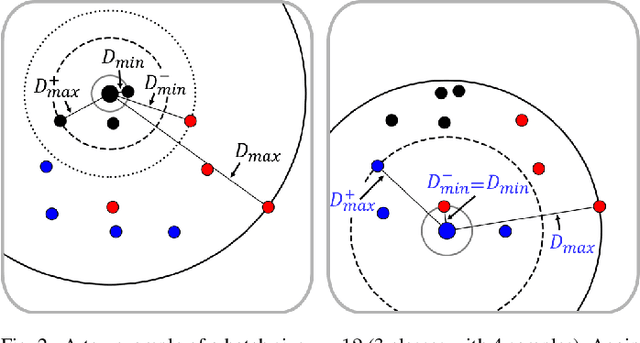
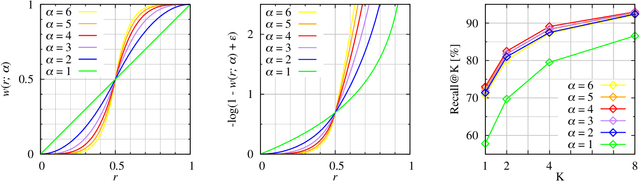
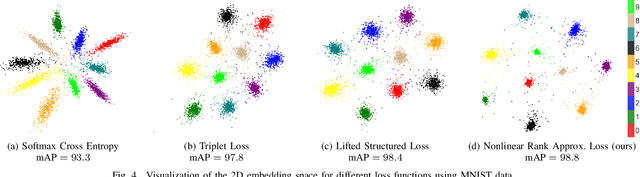
In recent years, deep metric learning has achieved promising results in learning high dimensional semantic feature embeddings where the spatial relationships of the feature vectors match the visual similarities of the images. Similarity search for images is performed by determining the vectors with the smallest distances to a query vector. However, high retrieval quality does not depend on the actual distances of the feature vectors, but rather on the ranking order of the feature vectors from similar images. In this paper, we introduce a metric learning algorithm that focuses on identifying and modifying those feature vectors that most strongly affect the retrieval quality. We compute normalized approximated ranks and convert them to similarities by applying a nonlinear transfer function. These similarities are used in a newly proposed loss function that better contracts similar and disperses dissimilar samples. Experiments demonstrate significant improvement over existing deep feature embedding methods on the CUB-200-2011, Cars196, and Stanford Online Products data sets for all embedding sizes.