 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatte-Mix: Measuring Sentence Semantic Similarity with Latent Categorical Mixtures
Oct 21, 2020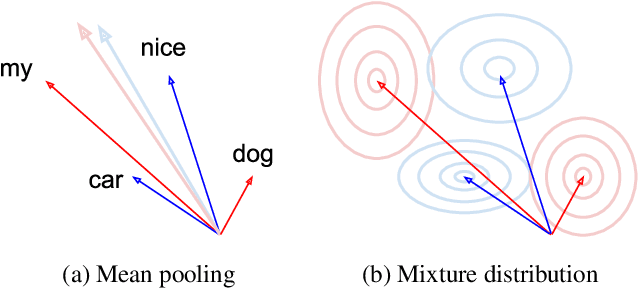
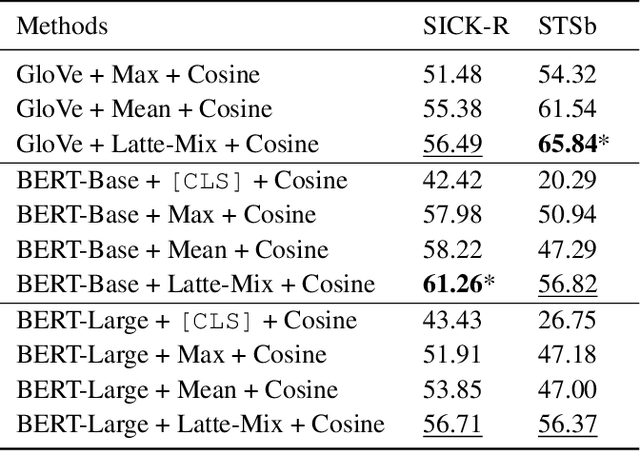
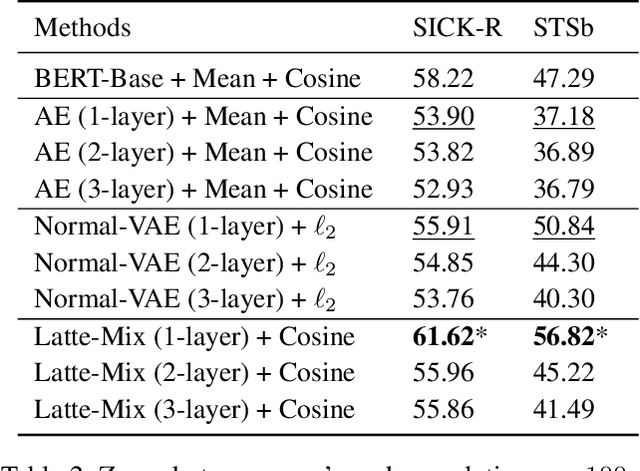
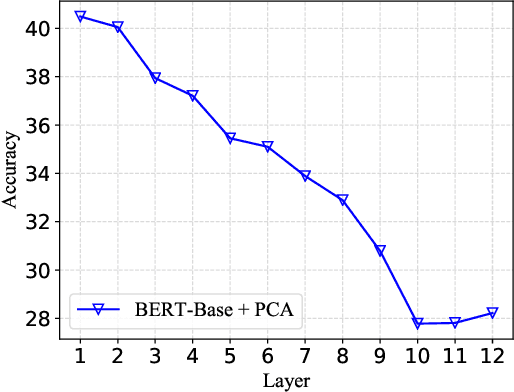
Measuring sentence semantic similarity using pre-trained language models such as BERT generally yields unsatisfactory zero-shot performance, and one main reason is ineffective token aggregation methods such as mean pooling. In this paper, we demonstrate under a Bayesian framework that distance between primitive statistics such as the mean of word embeddings are fundamentally flawed for capturing sentence-level semantic similarity. To remedy this issue, we propose to learn a categorical variational autoencoder (VAE) based on off-the-shelf pre-trained language models. We theoretically prove that measuring the distance between the latent categorical mixtures, namely Latte-Mix, can better reflect the true sentence semantic similarity. In addition, our Bayesian framework provides explanations for why models finetuned on labelled sentence pairs have better zero-shot performance. We also empirically demonstrate that these finetuned models could be further improved by Latte-Mix. Our method not only yields the state-of-the-art zero-shot performance on semantic similarity datasets such as STS, but also enjoy the benefits of fast training and having small memory footprints.