 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent deep reinforcement learning with centralized training and decentralized execution for transportation infrastructure management
Jan 23, 2024We present a multi-agent Deep Reinforcement Learning (DRL) framework for managing large transportation infrastructure systems over their life-cycle. Life-cycle management of such engineering systems is a computationally intensive task, requiring appropriate sequential inspection and maintenance decisions able to reduce long-term risks and costs, while dealing with different uncertainties and constraints that lie in high-dimensional spaces. To date, static age- or condition-based maintenance methods and risk-based or periodic inspection plans have mostly addressed this class of optimization problems. However, optimality, scalability, and uncertainty limitations are often manifested under such approaches. The optimization problem in this work is cast in the framework of constrained Partially Observable Markov Decision Processes (POMDPs), which provides a comprehensive mathematical basis for stochastic sequential decision settings with observation uncertainties, risk considerations, and limited resources. To address significantly large state and action spaces, a Deep Decentralized Multi-agent Actor-Critic (DDMAC) DRL method with Centralized Training and Decentralized Execution (CTDE), termed as DDMAC-CTDE is developed. The performance strengths of the DDMAC-CTDE method are demonstrated in a generally representative and realistic example application of an existing transportation network in Virginia, USA. The network includes several bridge and pavement components with nonstationary degradation, agency-imposed constraints, and traffic delay and risk considerations. Compared to traditional management policies for transportation networks, the proposed DDMAC-CTDE method vastly outperforms its counterparts. Overall, the proposed algorithmic framework provides near optimal solutions for transportation infrastructure management under real-world constraints and complexities.
Optimal Inspection and Maintenance Planning for Deteriorating Structures through Dynamic Bayesian Networks and Markov Decision Processes
Sep 09, 2020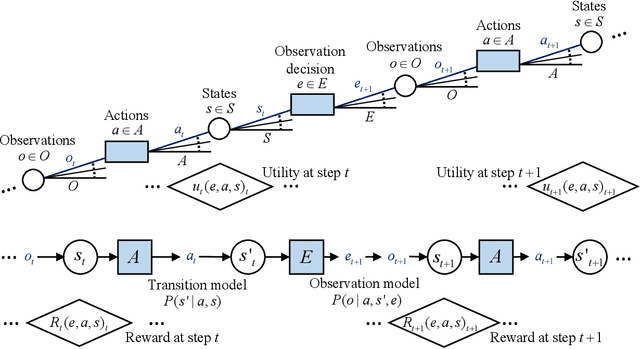


Civil and maritime engineering systems, among others, from bridges to offshore platforms and wind turbines, must be efficiently managed as they are exposed to deterioration mechanisms throughout their operational life, such as fatigue or corrosion. Identifying optimal inspection and maintenance policies demands the solution of a complex sequential decision-making problem under uncertainty, with the main objective of efficiently controlling the risk associated with structural failures. Addressing this complexity, risk-based inspection planning methodologies, supported often by dynamic Bayesian networks, evaluate a set of pre-defined heuristic decision rules to reasonably simplify the decision problem. However, the resulting policies may be compromised by the limited space considered in the definition of the decision rules. Avoiding this limitation, Partially Observable Markov Decision Processes (POMDPs) provide a principled mathematical methodology for stochastic optimal control under uncertain action outcomes and observations, in which the optimal actions are prescribed as a function of the entire, dynamically updated, state probability distribution. In this paper, we combine dynamic Bayesian networks with POMDPs in a joint framework for optimal inspection and maintenance planning, and we provide the formulation for developing both infinite and finite horizon POMDPs in a structural reliability context. The proposed methodology is implemented and tested for the case of a structural component subject to fatigue deterioration, demonstrating the capability of state-of-the-art point-based POMDP solvers for solving the underlying planning optimization problem. Within the numerical experiments, POMDP and heuristic-based policies are thoroughly compared, and results showcase that POMDPs achieve substantially lower costs as compared to their counterparts, even for traditional problem settings.
Deep reinforcement learning driven inspection and maintenance planning under incomplete information and constraints
Jul 02, 2020


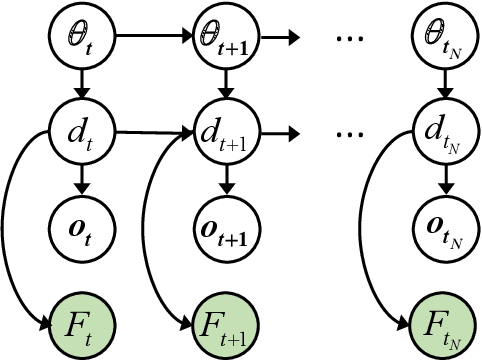
Determination of inspection and maintenance policies for minimizing long-term risks and costs in deteriorating engineering environments constitutes a complex optimization problem. Major computational challenges include the (i) curse of dimensionality, due to exponential scaling of state/action set cardinalities with the number of components; (ii) curse of history, related to exponentially growing decision-trees with the number of decision-steps; (iii) presence of state uncertainties, induced by inherent environment stochasticity and variability of inspection/monitoring measurements; (iv) presence of constraints, pertaining to stochastic long-term limitations, due to resource scarcity and other infeasible/undesirable system responses. In this work, these challenges are addressed within a joint framework of constrained Partially Observable Markov Decision Processes (POMDP) and multi-agent Deep Reinforcement Learning (DRL). POMDPs optimally tackle (ii)-(iii), combining stochastic dynamic programming with Bayesian inference principles. Multi-agent DRL addresses (i), through deep function parametrizations and decentralized control assumptions. Challenge (iv) is herein handled through proper state augmentation and Lagrangian relaxation, with emphasis on life-cycle risk-based constraints and budget limitations. The underlying algorithmic steps are provided, and the proposed framework is found to outperform well-established policy baselines and facilitate adept prescription of inspection and intervention actions, in cases where decisions must be made in the most resource- and risk-aware manner.
Value of structural health monitoring quantification in partially observable stochastic environments
Dec 28, 2019



Sequential decision-making under uncertainty for optimal life-cycle control of deteriorating engineering systems and infrastructure entails two fundamental classes of decisions. The first class pertains to the various structural interventions, which can directly modify the existing properties of the system, while the second class refers to prescribing appropriate inspection and monitoring schemes, which are essential for updating our existing knowledge about the system states. The latter have to rely on quantifiable measures of efficiency, determined on the basis of objective criteria that, among others, consider the Value of Information (VoI) of different observational strategies, and the Value of Structural Health Monitoring (VoSHM) over the entire system life-cycle. In this work, we present general solutions for quantifying the VoI and VoSHM in partially observable stochastic domains, and although our definitions and methodology are general, we are particularly emphasizing and describing the role of Partially Observable Markov Decision Processes (POMDPs) in solving this problem, due to their advantageous theoretical and practical attributes in estimating arbitrarily well globally optimal policies. POMDP formulations are articulated for different structural environments having shared intervention actions but diversified inspection and monitoring options, thus enabling VoI and VoSHM estimation through their differentiated stochastic optimal control policies. POMDP solutions are derived using point-based solvers, which can efficiently approximate the POMDP value functions through Bellman backups at selected reachable points of the belief space. The suggested methodology is applied on stationary and non-stationary deteriorating environments, with both infinite and finite planning horizons, featuring single- or multi-component engineering systems.
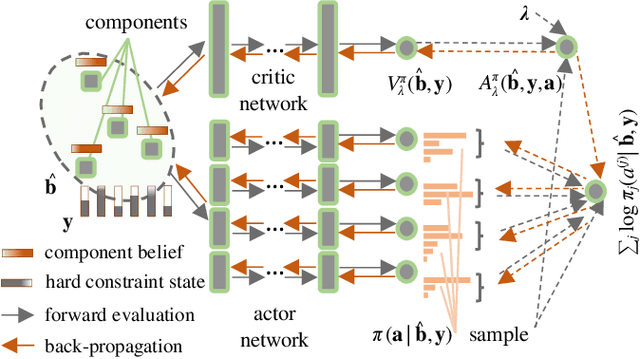
Managing engineering systems with large state and action spaces through deep reinforcement learning
Nov 05, 2018



Decision-making for engineering systems can be efficiently formulated as a Markov Decision Process (MDP) or a Partially Observable MDP (POMDP). Typical MDP and POMDP solution procedures utilize offline knowledge about the environment and provide detailed policies for relatively small systems with tractable state and action spaces. However, in large multi-component systems the sizes of these spaces easily explode, as system states and actions scale exponentially with the number of components, whereas environment dynamics are difficult to be described in explicit forms for the entire system and may only be accessible through numerical simulators. In this work, to address these issues, an integrated Deep Reinforcement Learning (DRL) framework is introduced. The Deep Centralized Multi-agent Actor Critic (DCMAC) is developed, an off-policy actor-critic DRL approach, providing efficient life-cycle policies for large multi-component systems operating in high-dimensional spaces. Apart from deep function approximations that parametrize large state spaces, DCMAC also adopts a factorized representation of the system actions, being able to designate individualized component- and subsystem-level decisions, while maintaining a centralized value function for the entire system. DCMAC compares well against Deep Q-Network (DQN) solutions and exact policies, where applicable, and outperforms optimized baselines that are based on time-based, condition-based and periodic policies.