 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeclip2latent: Text driven sampling of a pre-trained StyleGAN using denoising diffusion and CLIP
Oct 05, 2022

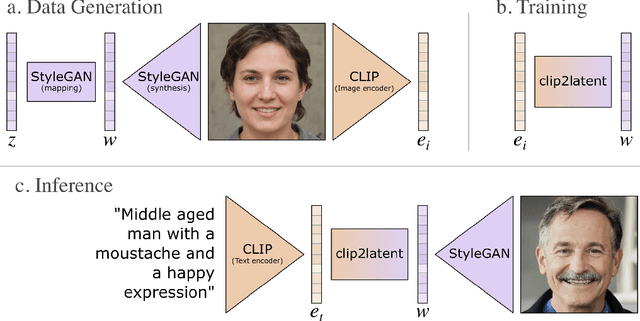

We introduce a new method to efficiently create text-to-image models from a pre-trained CLIP and StyleGAN. It enables text driven sampling with an existing generative model without any external data or fine-tuning. This is achieved by training a diffusion model conditioned on CLIP embeddings to sample latent vectors of a pre-trained StyleGAN, which we call clip2latent. We leverage the alignment between CLIP's image and text embeddings to avoid the need for any text labelled data for training the conditional diffusion model. We demonstrate that clip2latent allows us to generate high-resolution (1024x1024 pixels) images based on text prompts with fast sampling, high image quality, and low training compute and data requirements. We also show that the use of the well studied StyleGAN architecture, without further fine-tuning, allows us to directly apply existing methods to control and modify the generated images adding a further layer of control to our text-to-image pipeline.
Resolution Dependent GAN Interpolation for Controllable Image Synthesis Between Domains
Oct 20, 2020
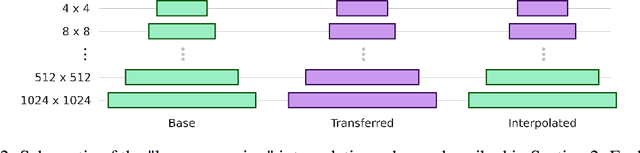


GANs can generate photo-realistic images from the domain of their training data. However, those wanting to use them for creative purposes often want to generate imagery from a truly novel domain, a task which GANs are inherently unable to do. It is also desirable to have a level of control so that there is a degree of artistic direction rather than purely curation of random results. Here we present a method for interpolating between generative models of the StyleGAN architecture in a resolution dependent manner. This allows us to generate images from an entirely novel domain and do this with a degree of control over the nature of the output.