 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrospective Counterfactual Prediction by Conditioning on the Factual Outcome: A Cross-World Approach
Mar 28, 2026Retrospective causal questions ask what would have happened to an observed individual had they received a different treatment. We study the problem of estimating $μ(x,y)=\mathbb{E}[Y(1)\mid X=x,Y(0)=y]$, the expected counterfactual outcome for an individual with covariates $x$ and observed outcome $y$, and constructing valid prediction intervals under the Neyman-Rubin superpopulation model. This quantity is generally not identified without additional assumptions. To link the observed and unobserved potential outcomes, we work with a cross-world correlation $ρ(x)=cor(Y(1),Y(0)\mid X=x)$; plausible bounds on $ρ(x)$ enable a principled approach to this otherwise unidentified problem. We introduce retrospective counterfactual estimators $\hatμ_ρ(x,y)$ and prediction intervals $C_ρ(x,y)$ that asymptotically satisfy $P[Y(1)\in C_ρ(x,y)\mid X=x, Y(0)=y]\ge1-α$ under standard causal assumptions. Many common baselines implicitly correspond to endpoint choices $ρ=0$ or $ρ=1$ (ignoring the factual outcome or treating the counterfactual as a shifted factual outcome). Interpolating between these cases through cross-world dependence yields substantial gains in both theory and practice.
Granger Causality in Extremes
Jul 12, 2024


We introduce a rigorous mathematical framework for Granger causality in extremes, designed to identify causal links from extreme events in time series. Granger causality plays a pivotal role in uncovering directional relationships among time-varying variables. While this notion gains heightened importance during extreme and highly volatile periods, state-of-the-art methods primarily focus on causality within the body of the distribution, often overlooking causal mechanisms that manifest only during extreme events. Our framework is designed to infer causality mainly from extreme events by leveraging the causal tail coefficient. We establish equivalences between causality in extremes and other causal concepts, including (classical) Granger causality, Sims causality, and structural causality. We prove other key properties of Granger causality in extremes and show that the framework is especially helpful under the presence of hidden confounders. We also propose a novel inference method for detecting the presence of Granger causality in extremes from data. Our method is model-free, can handle non-linear and high-dimensional time series, outperforms current state-of-the-art methods in all considered setups, both in performance and speed, and was found to uncover coherent effects when applied to financial and extreme weather observations.
Structural restrictions in local causal discovery: identifying direct causes of a target variable
Jul 29, 2023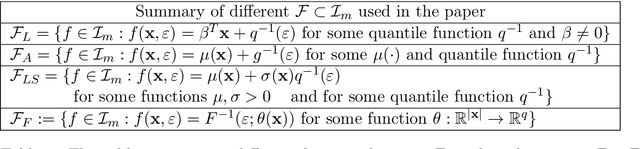
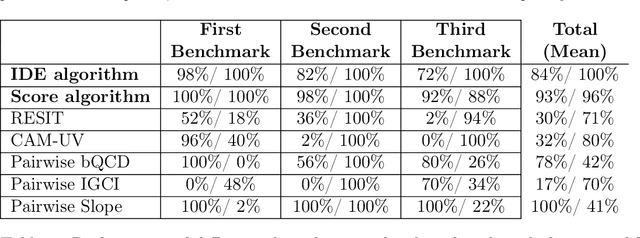
We consider the problem of learning a set of direct causes of a target variable from an observational joint distribution. Learning directed acyclic graphs (DAGs) that represent the causal structure is a fundamental problem in science. Several results are known when the full DAG is identifiable from the distribution, such as assuming a nonlinear Gaussian data-generating process. Often, we are only interested in identifying the direct causes of one target variable (local causal structure), not the full DAG. In this paper, we discuss different assumptions for the data-generating process of the target variable under which the set of direct causes is identifiable from the distribution. While doing so, we put essentially no assumptions on the variables other than the target variable. In addition to the novel identifiability results, we provide two practical algorithms for estimating the direct causes from a finite random sample and demonstrate their effectiveness on several benchmark datasets. We apply this framework to learn direct causes of the reduction in fertility rates in different countries.