 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Scene Deblurring Base on Continuous Cross-Layer Attention Transmission
Jun 23, 2022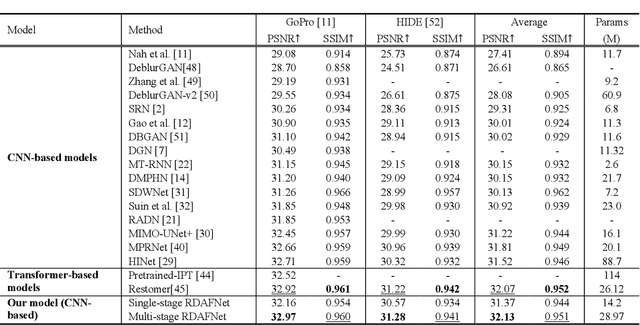


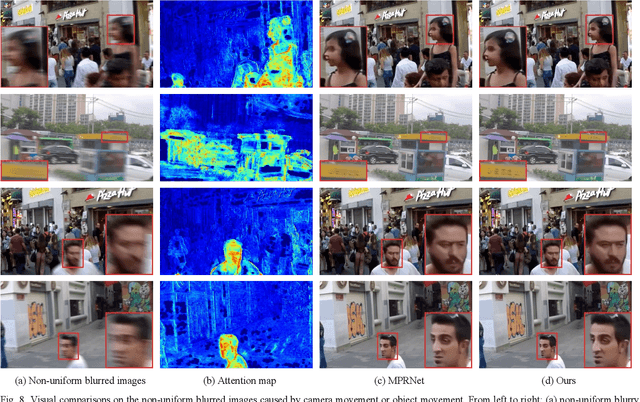
The deep convolutional neural networks (CNNs) using attention mechanism have achieved great success for dynamic scene deblurring. In most of these networks, only the features refined by the attention maps can be passed to the next layer and the attention maps of different layers are separated from each other, which does not make full use of the attention information from different layers in the CNN. To address this problem, we introduce a new continuous cross-layer attention transmission (CCLAT) mechanism that can exploit hierarchical attention information from all the convolutional layers. Based on the CCLAT mechanism, we use a very simple attention module to construct a novel residual dense attention fusion block (RDAFB). In RDAFB, the attention maps inferred from the outputs of the preceding RDAFB and each layer are directly connected to the subsequent ones, leading to a CRLAT mechanism. Taking RDAFB as the building block, we design an effective architecture for dynamic scene deblurring named RDAFNet. The experiments on benchmark datasets show that the proposed model outperforms the state-of-the-art deblurring approaches, and demonstrate the effectiveness of CCLAT mechanism. The source code is available on: https://github.com/xjmz6/RDAFNet.