 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstration-Guided Continual Reinforcement Learning in Dynamic Environments
Dec 21, 2025Reinforcement learning (RL) excels in various applications but struggles in dynamic environments where the underlying Markov decision process evolves. Continual reinforcement learning (CRL) enables RL agents to continually learn and adapt to new tasks, but balancing stability (preserving prior knowledge) and plasticity (acquiring new knowledge) remains challenging. Existing methods primarily address the stability-plasticity dilemma through mechanisms where past knowledge influences optimization but rarely affects the agent's behavior directly, which may hinder effective knowledge reuse and efficient learning. In contrast, we propose demonstration-guided continual reinforcement learning (DGCRL), which stores prior knowledge in an external, self-evolving demonstration repository that directly guides RL exploration and adaptation. For each task, the agent dynamically selects the most relevant demonstration and follows a curriculum-based strategy to accelerate learning, gradually shifting from demonstration-guided exploration to fully self-exploration. Extensive experiments on 2D navigation and MuJoCo locomotion tasks demonstrate its superior average performance, enhanced knowledge transfer, mitigation of forgetting, and training efficiency. The additional sensitivity analysis and ablation study further validate its effectiveness.
A Meta-Learning Approach for Multi-Objective Reinforcement Learning in Sustainable Home Environments
Jul 16, 2024Effective residential appliance scheduling is crucial for sustainable living. While multi-objective reinforcement learning (MORL) has proven effective in balancing user preferences in appliance scheduling, traditional MORL struggles with limited data in non-stationary residential settings characterized by renewable generation variations. Significant context shifts that can invalidate previously learned policies. To address these challenges, we extend state-of-the-art MORL algorithms with the meta-learning paradigm, enabling rapid, few-shot adaptation to shifting contexts. Additionally, we employ an auto-encoder (AE)-based unsupervised method to detect environment context changes. We have also developed a residential energy environment to evaluate our method using real-world data from London residential settings. This study not only assesses the application of MORL in residential appliance scheduling but also underscores the effectiveness of meta-learning in energy management. Our top-performing method significantly surpasses the best baseline, while the trained model saves 3.28% on electricity bills, a 2.74% increase in user comfort, and a 5.9% improvement in expected utility. Additionally, it reduces the sparsity of solutions by 62.44%. Remarkably, these gains were accomplished using 96.71% less training data and 61.1% fewer training steps.
Demonstration Guided Multi-Objective Reinforcement Learning
Apr 05, 2024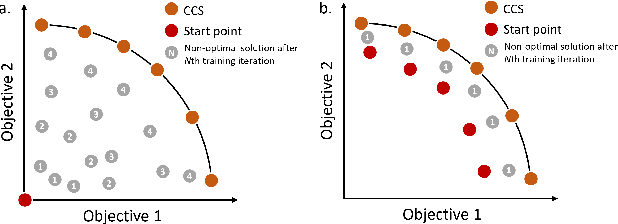
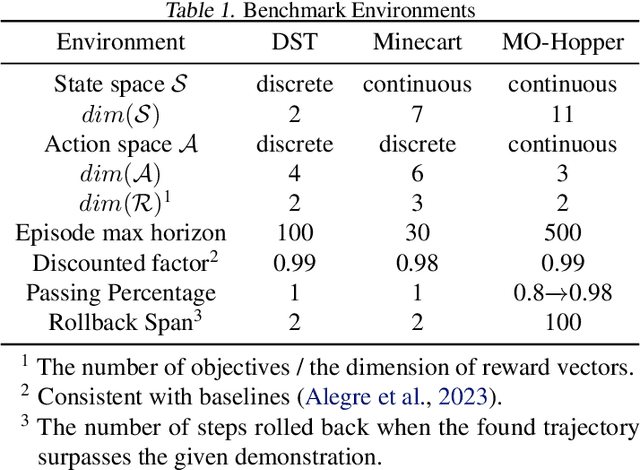
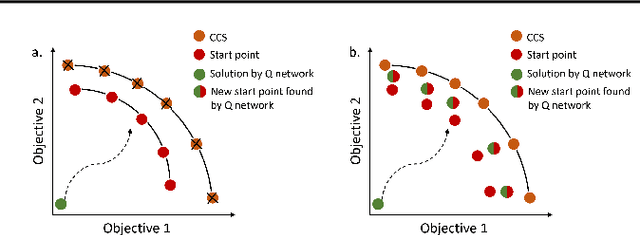
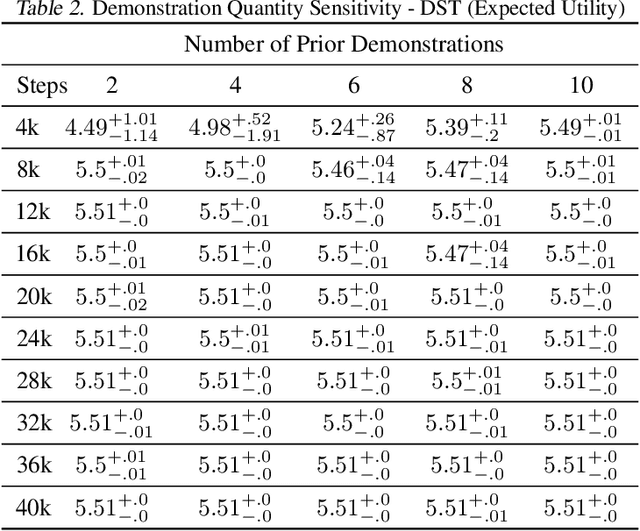
Multi-objective reinforcement learning (MORL) is increasingly relevant due to its resemblance to real-world scenarios requiring trade-offs between multiple objectives. Catering to diverse user preferences, traditional reinforcement learning faces amplified challenges in MORL. To address the difficulty of training policies from scratch in MORL, we introduce demonstration-guided multi-objective reinforcement learning (DG-MORL). This novel approach utilizes prior demonstrations, aligns them with user preferences via corner weight support, and incorporates a self-evolving mechanism to refine suboptimal demonstrations. Our empirical studies demonstrate DG-MORL's superiority over existing MORL algorithms, establishing its robustness and efficacy, particularly under challenging conditions. We also provide an upper bound of the algorithm's sample complexity.
Go-Explore for Residential Energy Management
Jan 15, 2024Reinforcement learning is commonly applied in residential energy management, particularly for optimizing energy costs. However, RL agents often face challenges when dealing with deceptive and sparse rewards in the energy control domain, especially with stochastic rewards. In such situations, thorough exploration becomes crucial for learning an optimal policy. Unfortunately, the exploration mechanism can be misled by deceptive reward signals, making thorough exploration difficult. Go-Explore is a family of algorithms which combines planning methods and reinforcement learning methods to achieve efficient exploration. We use the Go-Explore algorithm to solve the cost-saving task in residential energy management problems and achieve an improvement of up to 19.84\% compared to the well-known reinforcement learning algorithms.
Inferring Preferences from Demonstrations in Multi-Objective Residential Energy Management
Jan 15, 2024It is often challenging for a user to articulate their preferences accurately in multi-objective decision-making problems. Demonstration-based preference inference (DemoPI) is a promising approach to mitigate this problem. Understanding the behaviours and values of energy customers is an example of a scenario where preference inference can be used to gain insights into the values of energy customers with multiple objectives, e.g. cost and comfort. In this work, we applied the state-of-art DemoPI method, i.e., the dynamic weight-based preference inference (DWPI) algorithm in a multi-objective residential energy consumption setting to infer preferences from energy consumption demonstrations by simulated users following a rule-based approach. According to our experimental results, the DWPI model achieves accurate demonstration-based preference inferring in three scenarios. These advancements enhance the usability and effectiveness of multi-objective reinforcement learning (MORL) in energy management, enabling more intuitive and user-friendly preference specifications, and opening the door for DWPI to be applied in real-world settings.
Preference Inference from Demonstration in Multi-objective Multi-agent Decision Making
Apr 27, 2023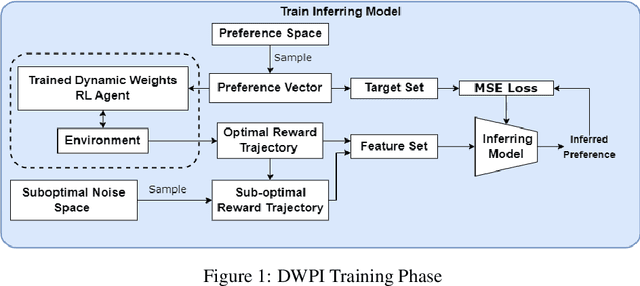

It is challenging to quantify numerical preferences for different objectives in a multi-objective decision-making problem. However, the demonstrations of a user are often accessible. We propose an algorithm to infer linear preference weights from either optimal or near-optimal demonstrations. The algorithm is evaluated in three environments with two baseline methods. Empirical results demonstrate significant improvements compared to the baseline algorithms, in terms of both time requirements and accuracy of the inferred preferences. In future work, we plan to evaluate the algorithm's effectiveness in a multi-agent system, where one of the agents is enabled to infer the preferences of an opponent using our preference inference algorithm.
Inferring Preferences from Demonstrations in Multi-objective Reinforcement Learning: A Dynamic Weight-based Approach
Apr 27, 2023



Many decision-making problems feature multiple objectives. In such problems, it is not always possible to know the preferences of a decision-maker for different objectives. However, it is often possible to observe the behavior of decision-makers. In multi-objective decision-making, preference inference is the process of inferring the preferences of a decision-maker for different objectives. This research proposes a Dynamic Weight-based Preference Inference (DWPI) algorithm that can infer the preferences of agents acting in multi-objective decision-making problems, based on observed behavior trajectories in the environment. The proposed method is evaluated on three multi-objective Markov decision processes: Deep Sea Treasure, Traffic, and Item Gathering. The performance of the proposed DWPI approach is compared to two existing preference inference methods from the literature, and empirical results demonstrate significant improvements compared to the baseline algorithms, in terms of both time requirements and accuracy of the inferred preferences. The Dynamic Weight-based Preference Inference algorithm also maintains its performance when inferring preferences for sub-optimal behavior demonstrations. In addition to its impressive performance, the Dynamic Weight-based Preference Inference algorithm does not require any interactions during training with the agent whose preferences are inferred, all that is required is a trajectory of observed behavior.