 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
Policy Optimization and Multi-agent Reinforcement Learning for Mean-variance Team Stochastic Games
Mar 28, 2025
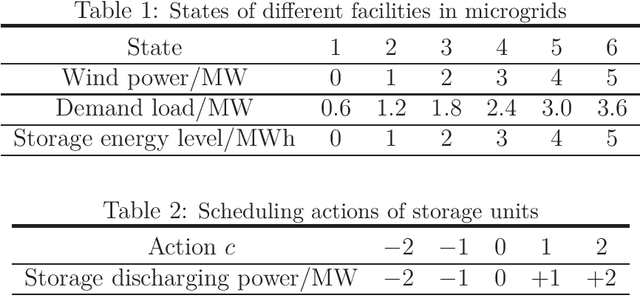


We study a long-run mean-variance team stochastic game (MV-TSG), where each agent shares a common mean-variance objective for the system and takes actions independently to maximize it. MV-TSG has two main challenges. First, the variance metric is neither additive nor Markovian in a dynamic setting. Second, simultaneous policy updates of all agents lead to a non-stationary environment for each individual agent. Both challenges make dynamic programming inapplicable. In this paper, we study MV-TSGs from the perspective of sensitivity-based optimization. The performance difference and performance derivative formulas for joint policies are derived, which provide optimization information for MV-TSGs. We prove the existence of a deterministic Nash policy for this problem. Subsequently, we propose a Mean-Variance Multi-Agent Policy Iteration (MV-MAPI) algorithm with a sequential update scheme, where individual agent policies are updated one by one in a given order. We prove that the MV-MAPI algorithm converges to a first-order stationary point of the objective function. By analyzing the local geometry of stationary points, we derive specific conditions for stationary points to be (local) Nash equilibria, and further, strict local optima. To solve large-scale MV-TSGs in scenarios with unknown environmental parameters, we extend the idea of trust region methods to MV-MAPI and develop a multi-agent reinforcement learning algorithm named Mean-Variance Multi-Agent Trust Region Policy Optimization (MV-MATRPO). We derive a performance lower bound for each update of joint policies. Finally, numerical experiments on energy management in multiple microgrid systems are conducted.