 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration of Distributionally Robust Empirical Optimization Models
Nov 17, 2017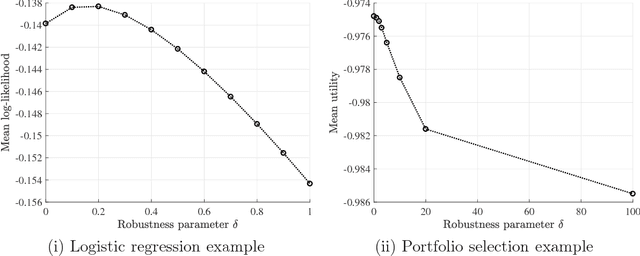
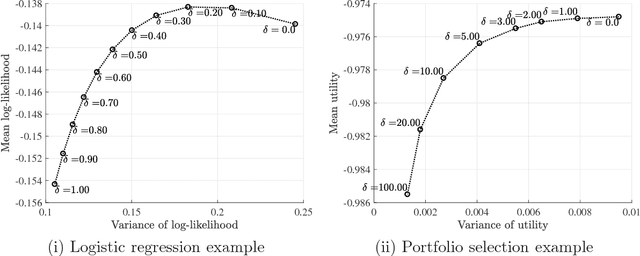
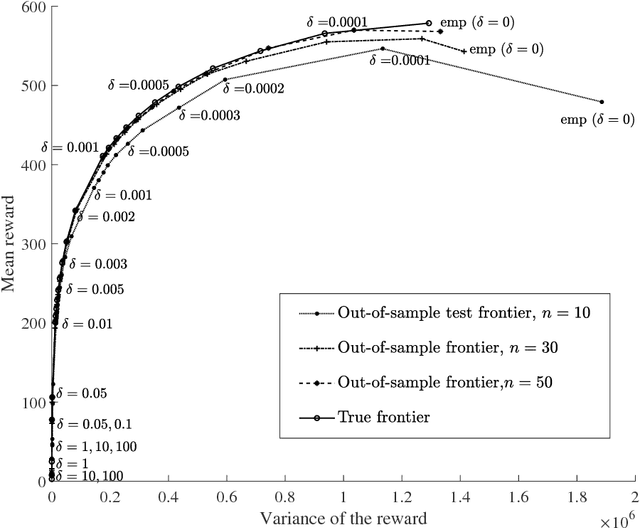
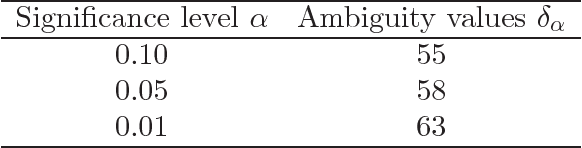
In this paper, we study the out-of-sample properties of robust empirical optimization and develop a theory for data-driven calibration of the robustness parameter for worst-case maximization problems with concave reward functions. Building on the intuition that robust optimization reduces the sensitivity of the expected reward to errors in the model by controlling the spread of the reward distribution, we show that the first-order benefit of little bit of robustness is a significant reduction in the variance of the out-of-sample reward while the corresponding impact on the mean is almost an order of magnitude smaller. One implication is that a substantial reduction in the variance of the out-of-sample reward (i.e. sensitivity of the expected reward to model misspecification) is possible at little cost if the robustness parameter is properly calibrated. To this end, we introduce the notion of a robust mean-variance frontier to select the robustness parameter and show that it can be approximated using resampling methods like the bootstrap. Our examples also show that open loop calibration methods (e.g. selecting a 90% confidence level regardless of the data and objective function) can lead to solutions that are very conservative out-of-sample.