 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA data-driven approach to beating SAA out-of-sample
May 26, 2021While solutions of Distributionally Robust Optimization (DRO) problems can sometimes have a higher out-of-sample expected reward than the Sample Average Approximation (SAA), there is no guarantee. In this paper, we introduce the class of Distributionally Optimistic Optimization (DOO) models, and show that it is always possible to "beat" SAA out-of-sample if we consider not just worst-case (DRO) models but also best-case (DOO) ones. We also show, however, that this comes at a cost: Optimistic solutions are more sensitive to model error than either worst-case or SAA optimizers, and hence are less robust.
Worst-case sensitivity
Oct 21, 2020
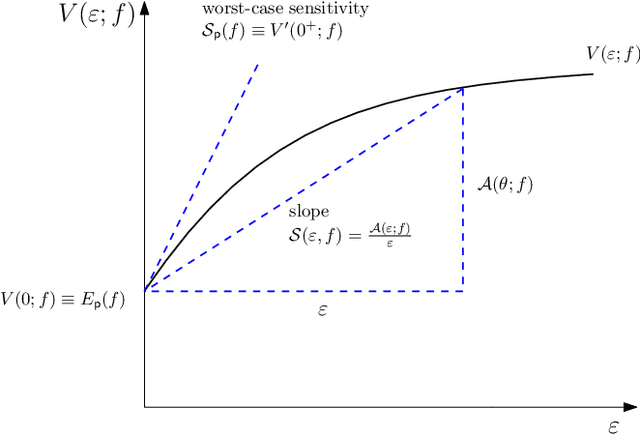
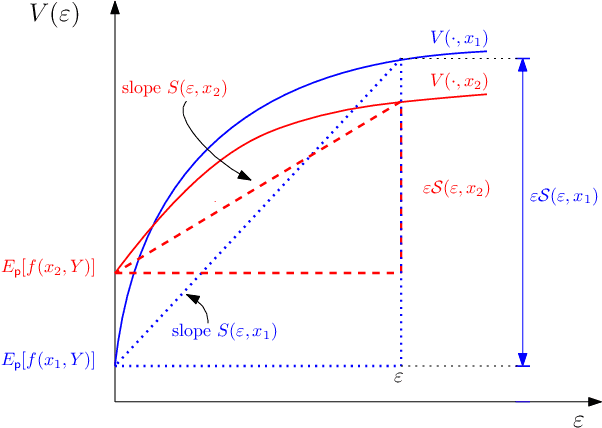

We introduce the notion of Worst-Case Sensitivity, defined as the worst-case rate of increase in the expected cost of a Distributionally Robust Optimization (DRO) model when the size of the uncertainty set vanishes. We show that worst-case sensitivity is a Generalized Measure of Deviation and that a large class of DRO models are essentially mean-(worst-case) sensitivity problems when uncertainty sets are small, unifying recent results on the relationship between DRO and regularized empirical optimization with worst-case sensitivity playing the role of the regularizer. More generally, DRO solutions can be sensitive to the family and size of the uncertainty set, and reflect the properties of its worst-case sensitivity. We derive closed-form expressions of worst-case sensitivity for well known uncertainty sets including smooth $\phi$-divergence, total variation, "budgeted" uncertainty sets, uncertainty sets corresponding to a convex combination of expected value and CVaR, and the Wasserstein metric. These can be used to select the uncertainty set and its size for a given application.
Calibration of Distributionally Robust Empirical Optimization Models
Nov 17, 2017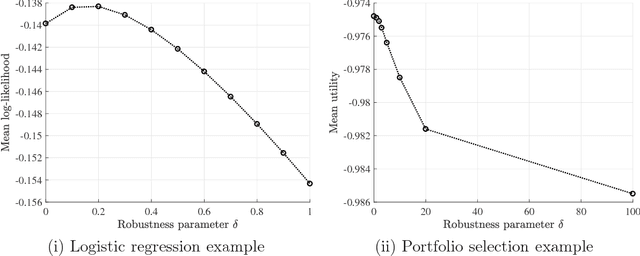
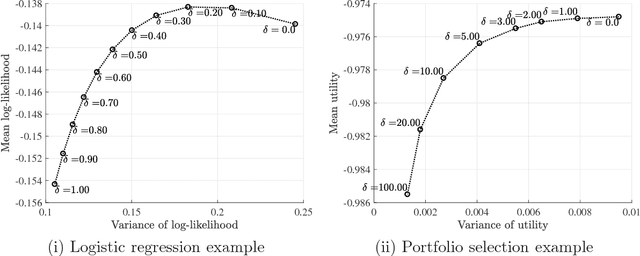
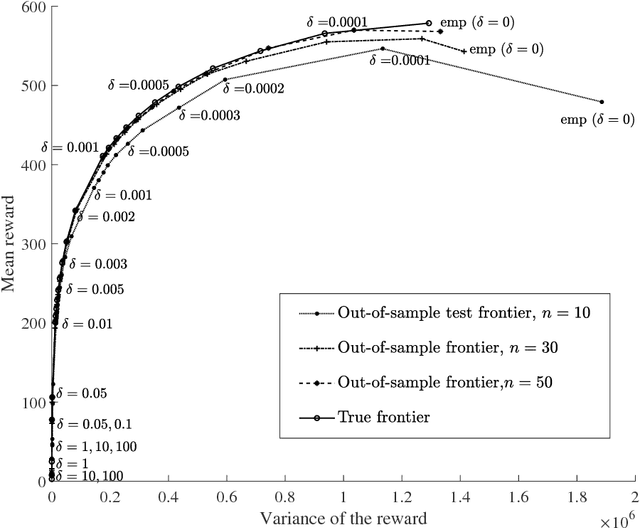
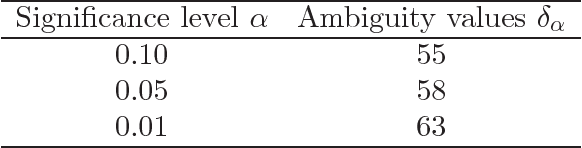
In this paper, we study the out-of-sample properties of robust empirical optimization and develop a theory for data-driven calibration of the robustness parameter for worst-case maximization problems with concave reward functions. Building on the intuition that robust optimization reduces the sensitivity of the expected reward to errors in the model by controlling the spread of the reward distribution, we show that the first-order benefit of little bit of robustness is a significant reduction in the variance of the out-of-sample reward while the corresponding impact on the mean is almost an order of magnitude smaller. One implication is that a substantial reduction in the variance of the out-of-sample reward (i.e. sensitivity of the expected reward to model misspecification) is possible at little cost if the robustness parameter is properly calibrated. To this end, we introduce the notion of a robust mean-variance frontier to select the robustness parameter and show that it can be approximated using resampling methods like the bootstrap. Our examples also show that open loop calibration methods (e.g. selecting a 90% confidence level regardless of the data and objective function) can lead to solutions that are very conservative out-of-sample.