 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildIng: A Wildlife Image Invariant Representation Model for Geographical Domain Shift
Jan 02, 2026Wildlife monitoring is crucial for studying biodiversity loss and climate change. Camera trap images provide a non-intrusive method for analyzing animal populations and identifying ecological patterns over time. However, manual analysis is time-consuming and resource-intensive. Deep learning, particularly foundation models, has been applied to automate wildlife identification, achieving strong performance when tested on data from the same geographical locations as their training sets. Yet, despite their promise, these models struggle to generalize to new geographical areas, leading to significant performance drops. For example, training an advanced vision-language model, such as CLIP with an adapter, on an African dataset achieves an accuracy of 84.77%. However, this performance drops significantly to 16.17% when the model is tested on an American dataset. This limitation partly arises because existing models rely predominantly on image-based representations, making them sensitive to geographical data distribution shifts, such as variation in background, lighting, and environmental conditions. To address this, we introduce WildIng, a Wildlife image Invariant representation model for geographical domain shift. WildIng integrates text descriptions with image features, creating a more robust representation to geographical domain shifts. By leveraging textual descriptions, our approach captures consistent semantic information, such as detailed descriptions of the appearance of the species, improving generalization across different geographical locations. Experiments show that WildIng enhances the accuracy of foundation models such as BioCLIP by 30% under geographical domain shift conditions. We evaluate WildIng on two datasets collected from different regions, namely America and Africa. The code and models are publicly available at https://github.com/Julian075/CATALOG/tree/WildIng.
CATALOG: A Camera Trap Language-guided Contrastive Learning Model
Dec 14, 2024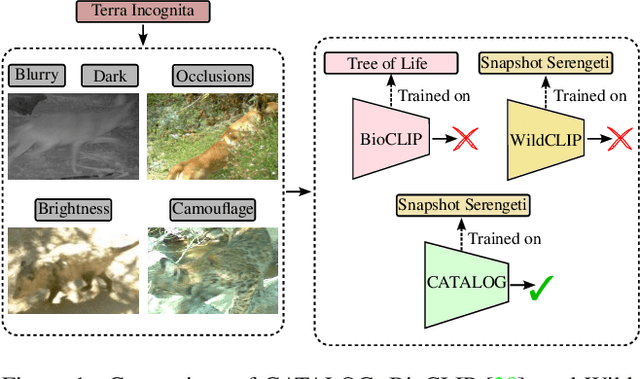
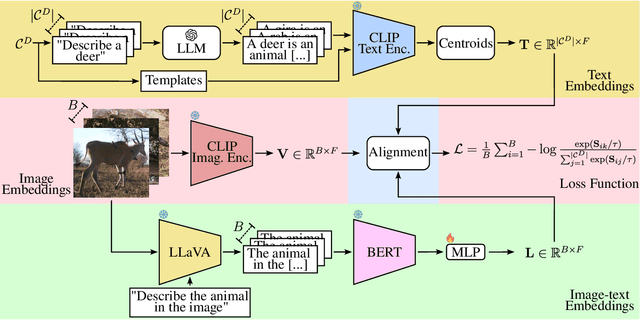
Foundation Models (FMs) have been successful in various computer vision tasks like image classification, object detection and image segmentation. However, these tasks remain challenging when these models are tested on datasets with different distributions from the training dataset, a problem known as domain shift. This is especially problematic for recognizing animal species in camera-trap images where we have variability in factors like lighting, camouflage and occlusions. In this paper, we propose the Camera Trap Language-guided Contrastive Learning (CATALOG) model to address these issues. Our approach combines multiple FMs to extract visual and textual features from camera-trap data and uses a contrastive loss function to train the model. We evaluate CATALOG on two benchmark datasets and show that it outperforms previous state-of-the-art methods in camera-trap image recognition, especially when the training and testing data have different animal species or come from different geographical areas. Our approach demonstrates the potential of using FMs in combination with multi-modal fusion and contrastive learning for addressing domain shifts in camera-trap image recognition. The code of CATALOG is publicly available at https://github.com/Julian075/CATALOG.