 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Explanation for Auto-Encoder Based Time-Series Anomaly Detection
Jan 03, 2025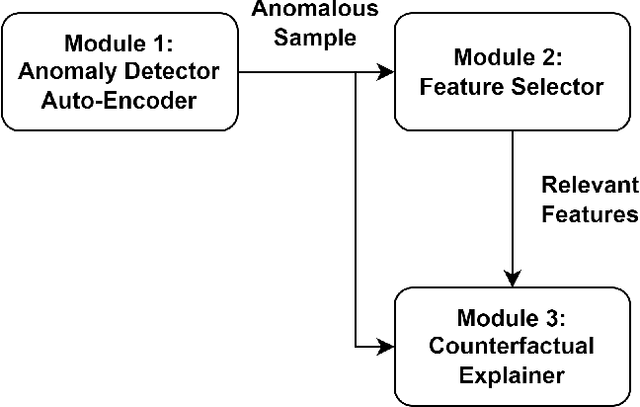


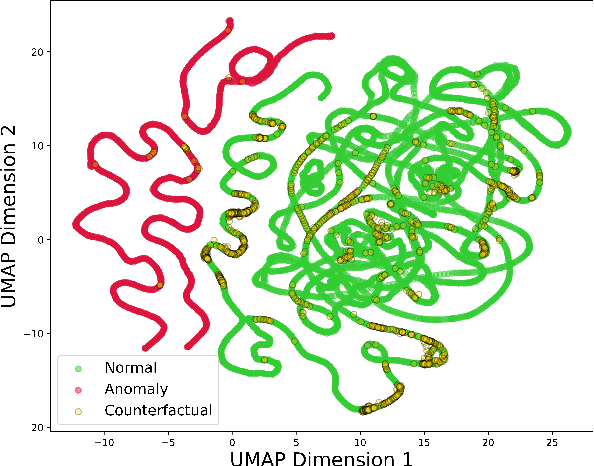
The complexity of modern electro-mechanical systems require the development of sophisticated diagnostic methods like anomaly detection capable of detecting deviations. Conventional anomaly detection approaches like signal processing and statistical modelling often struggle to effectively handle the intricacies of complex systems, particularly when dealing with multi-variate signals. In contrast, neural network-based anomaly detection methods, especially Auto-Encoders, have emerged as a compelling alternative, demonstrating remarkable performance. However, Auto-Encoders exhibit inherent opaqueness in their decision-making processes, hindering their practical implementation at scale. Addressing this opacity is essential for enhancing the interpretability and trustworthiness of anomaly detection models. In this work, we address this challenge by employing a feature selector to select features and counterfactual explanations to give a context to the model output. We tested this approach on the SKAB benchmark dataset and an industrial time-series dataset. The gradient based counterfactual explanation approach was evaluated via validity, sparsity and distance measures. Our experimental findings illustrate that our proposed counterfactual approach can offer meaningful and valuable insights into the model decision-making process, by explaining fewer signals compared to conventional approaches. These insights enhance the trustworthiness and interpretability of anomaly detection models.
* 8 pages, 6 figures, 6 tables, conference proceeding
Ensemble Neural Networks for Remaining Useful Life (RUL) Prediction
Sep 21, 2023A core part of maintenance planning is a monitoring system that provides a good prognosis on health and degradation, often expressed as remaining useful life (RUL). Most of the current data-driven approaches for RUL prediction focus on single-point prediction. These point prediction approaches do not include the probabilistic nature of the failure. The few probabilistic approaches to date either include the aleatoric uncertainty (which originates from the system), or the epistemic uncertainty (which originates from the model parameters), or both simultaneously as a total uncertainty. Here, we propose ensemble neural networks for probabilistic RUL predictions which considers both uncertainties and decouples these two uncertainties. These decoupled uncertainties are vital in knowing and interpreting the confidence of the predictions. This method is tested on NASA's turbofan jet engine CMAPSS data-set. Our results show how these uncertainties can be modeled and how to disentangle the contribution of aleatoric and epistemic uncertainty. Additionally, our approach is evaluated on different metrics and compared against the current state-of-the-art methods.
* 6 pages, 2 figures, 2 tables, conference proceeding
Modular Federated Learning
Sep 07, 2022



Federated learning is an approach to train machine learning models on the edge of the networks, as close as possible where the data is produced, motivated by the emerging problem of the inability to stream and centrally store the large amount of data produced by edge devices as well as by data privacy concerns. This learning paradigm is in need of robust algorithms to device heterogeneity and data heterogeneity. This paper proposes ModFL as a federated learning framework that splits the models into a configuration module and an operation module enabling federated learning of the individual modules. This modular approach makes it possible to extract knowlege from a group of heterogeneous devices as well as from non-IID data produced from its users. This approach can be viewed as an extension of the federated learning with personalisation layers FedPer framework that addresses data heterogeneity. We show that ModFL outperforms FedPer for non-IID data partitions of CIFAR-10 and STL-10 using CNNs. Our results on time-series data with HAPT, RWHAR, and WISDM datasets using RNNs remain inconclusive, we argue that the chosen datasets do not highlight the advantages of ModFL, but in the worst case scenario it performs as well as FedPer.