 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Voice Conversion by Separating Speaker and Content Representations with Instance Normalization
Apr 16, 2019

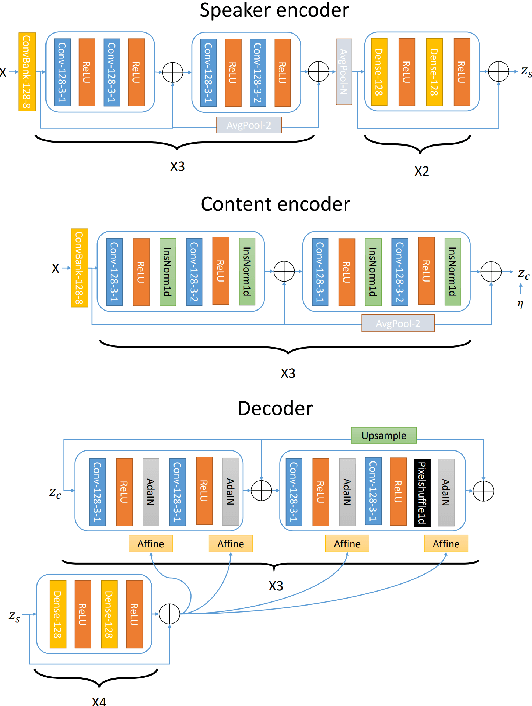
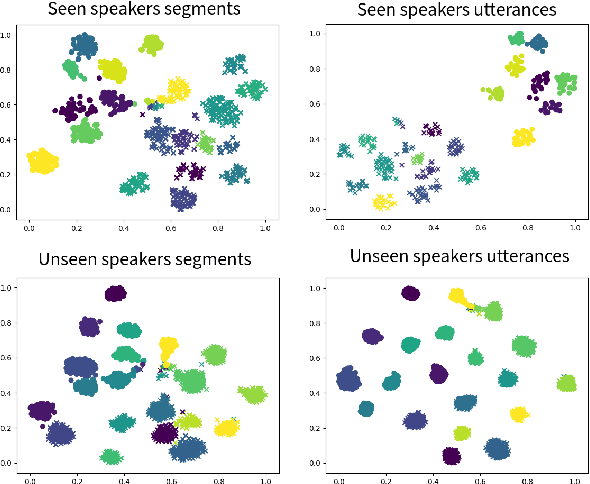
Recently, voice conversion (VC) without parallel data has been successfully adapted to multi-target scenario in which a single model is trained to convert the input voice to many different speakers. However, such model suffers from the limitation that it can only convert the voice to the speakers in the training data, which narrows down the applicable scenario of VC. In this paper, we proposed a novel one-shot VC approach which is able to perform VC by only an example utterance from source and target speaker respectively, and the source and target speaker do not even need to be seen during training. This is achieved by disentangling speaker and content representations with instance normalization (IN). Objective and subjective evaluation shows that our model is able to generate the voice similar to target speaker. In addition to the performance measurement, we also demonstrate that this model is able to learn meaningful speaker representations without any supervision.
Multi-target Voice Conversion without Parallel Data by Adversarially Learning Disentangled Audio Representations
Jun 24, 2018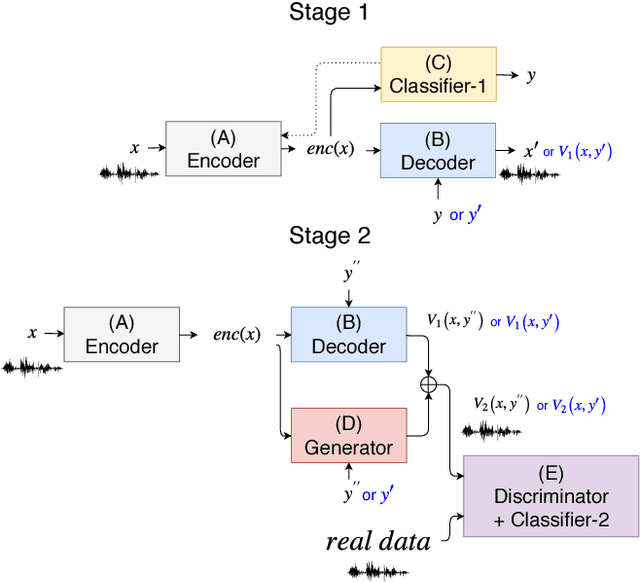
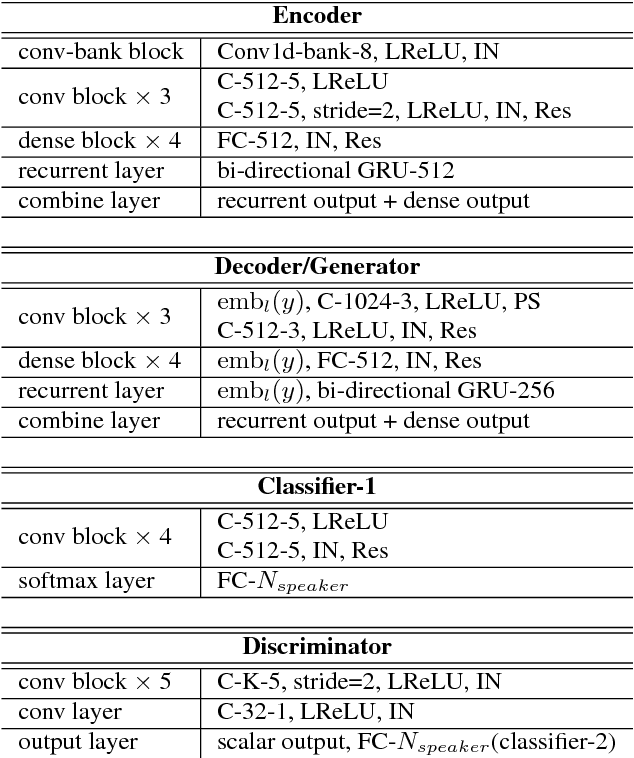
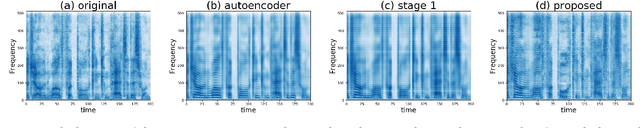
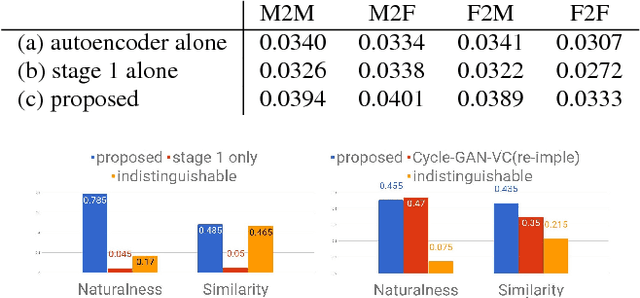
Recently, cycle-consistent adversarial network (Cycle-GAN) has been successfully applied to voice conversion to a different speaker without parallel data, although in those approaches an individual model is needed for each target speaker. In this paper, we propose an adversarial learning framework for voice conversion, with which a single model can be trained to convert the voice to many different speakers, all without parallel data, by separating the speaker characteristics from the linguistic content in speech signals. An autoencoder is first trained to extract speaker-independent latent representations and speaker embedding separately using another auxiliary speaker classifier to regularize the latent representation. The decoder then takes the speaker-independent latent representation and the target speaker embedding as the input to generate the voice of the target speaker with the linguistic content of the source utterance. The quality of decoder output is further improved by patching with the residual signal produced by another pair of generator and discriminator. A target speaker set size of 20 was tested in the preliminary experiments, and very good voice quality was obtained. Conventional voice conversion metrics are reported. We also show that the speaker information has been properly reduced from the latent representations.