 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIFT: Deep Restoration, ISP Fusion, and Tone-mapping
Apr 03, 2026Smartphone cameras have gained immense popularity with the adoption of high-resolution and high-dynamic range imaging. As a result, high-performance camera Image Signal Processors (ISPs) are crucial in generating high-quality images for the end user while keeping computational costs low. In this paper, we propose DRIFT (Deep Restoration, ISP Fusion, and Tone-mapping): an efficient AI mobile camera pipeline that generates high quality RGB images from hand-held raw captures. The first stage of DRIFT is a Multi-Frame Processing (MFP) network that is trained using a adversarial perceptual loss to perform multi-frame alignment, denoising, demosaicing, and super-resolution. Then, the output of DRIFT-MFP is processed by a novel deep-learning based tone-mapping (DRIFT-TM) solution that allows for tone tunability, ensures tone-consistency with a reference pipeline, and can be run efficiently for high-resolution images on a mobile device. We show qualitative and quantitative comparisons against state-of-the-art MFP and tone-mapping methods to demonstrate the effectiveness of our approach.
GenMFSR: Generative Multi-Frame Image Restoration and Super-Resolution
Mar 19, 2026Camera pipelines receive raw Bayer-format frames that need to be denoised, demosaiced, and often super-resolved. Multiple frames are captured to utilize natural hand tremors and enhance resolution. Multi-frame super-resolution is therefore a fundamental problem in camera pipelines. Existing adversarial methods are constrained by the quality of ground truth. We propose GenMFSR, the first Generative Multi-Frame Raw-to-RGB Super Resolution pipeline, that incorporates image priors from foundation models to obtain sub-pixel information for camera ISP applications. GenMFSR can align multiple raw frames, unlike existing single-frame super-resolution methods, and we propose a loss term that restricts generation to high-frequency regions in the raw domain, thus preventing low-frequency artifacts.
A subjective study of the perceptual acceptability of audio-video desynchronization in sports videos
Dec 03, 2022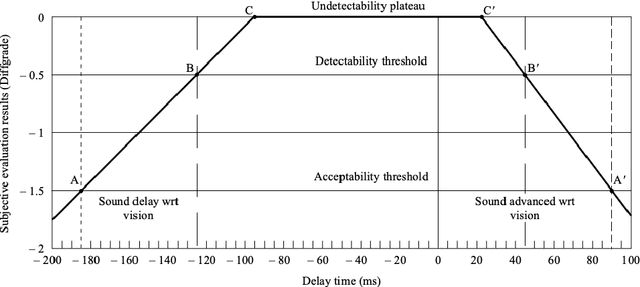
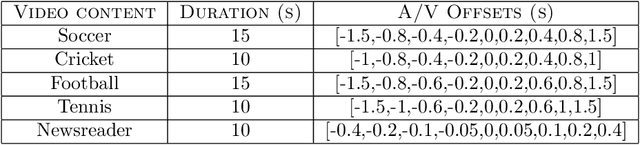
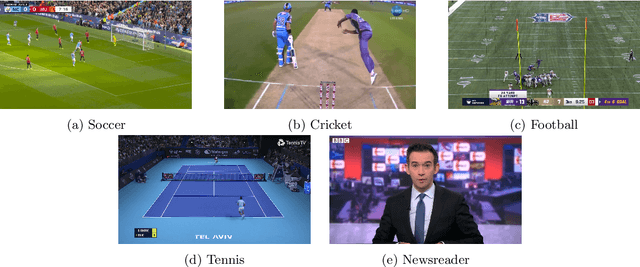

This paper presents the results of a study conducted on the perceptual acceptability of audio-video desynchronization for sports videos. The study was conducted with 45 videos generated by applying 8 audio-video offsets on 5 source contents. 20 subjects participated in the study. The results show that humans are more sensitive to audio-video offset errors for speech stimuli, and the complex events that occur in sports broadcasts have higher thresholds of acceptability. This suggests the tuning of audio-video synchronization requirements in broadcasting to the content of the broadcast.
Single Image Haze Removal Using Conditional Wasserstein Generative Adversarial Networks
Mar 01, 2019

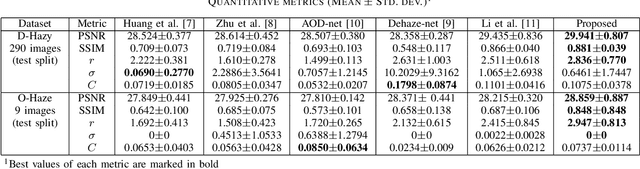
We present a method to restore a clear image from a haze-affected image using a Wasserstein generative adversarial network. As the problem is ill-conditioned, previous methods have required a prior on natural images or multiple images of the same scene. We train a generative adversarial network to learn the probability distribution of clear images conditioned on the haze-affected images using the Wasserstein loss function, using a gradient penalty to enforce the Lipschitz constraint. The method is data-adaptive, end-to-end, and requires no further processing or tuning of parameters. We also incorporate the use of a texture-based loss metric and the L1 loss to improve results, and show that our results are better than the current state-of-the-art.
Automatic segmentation of skin lesions using deep learning
Jul 13, 2018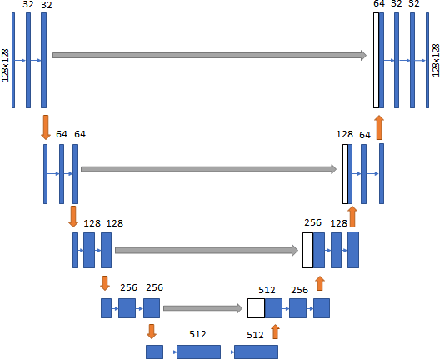
This paper summarizes the method used in our submission to Task 1 of the International Skin Imaging Collaboration's (ISIC) Skin Lesion Analysis Towards Melanoma Detection challenge held in 2018. We used a fully automated method to accurately segment lesion boundaries from dermoscopic images. A U-net deep learning network is trained on publicly available data from ISIC. We introduce the use of intensity, color, and texture enhancement operations as pre-processing steps and morphological operations and contour identification as post-processing steps.