 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReleasing the CRaQAn : An open-source dataset and dataset creation methodology using instruction-following models
Nov 27, 2023



Instruction-following language models demand robust methodologies for information retrieval to augment instructions for question-answering applications. A primary challenge is the resolution of coreferences in the context of chunking strategies for long documents. The critical barrier to experimentation of handling coreferences is a lack of open source datasets, specifically in question-answering tasks that require coreference resolution. In this work we present our Coreference Resolution in Question-Answering (CRaQAn) dataset, an open-source dataset that caters to the nuanced information retrieval requirements of coreference resolution in question-answering tasks by providing over 250 question-answer pairs containing coreferences. To develop this dataset, we developed a novel approach for creating high-quality datasets using an instruction-following model (GPT-4) and a Recursive Criticism and Improvement Loop.
Neural Conditional Event Time Models
Apr 03, 2020
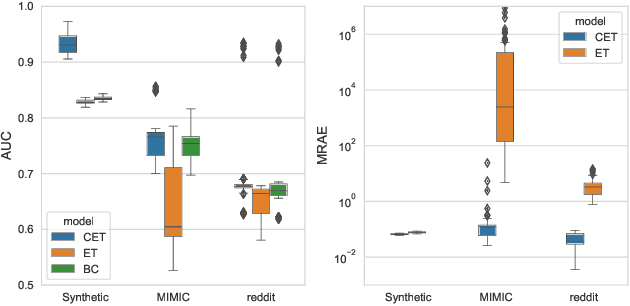

Event time models predict occurrence times of an event of interest based on known features. Recent work has demonstrated that neural networks achieve state-of-the-art event time predictions in a variety of settings. However, standard event time models suppose that the event occurs, eventually, in all cases. Consequently, no distinction is made between a) the probability of event occurrence, and b) the predicted time of occurrence. This distinction is critical when predicting medical diagnoses, equipment defects, social media posts, and other events that or may not occur, and for which the features affecting a) may be different from those affecting b). In this work, we develop a conditional event time model that distinguishes between these components, implement it as a neural network with a binary stochastic layer representing finite event occurrence, and show how it may be learned from right-censored event times via maximum likelihood estimation. Results demonstrate superior event occurrence and event time predictions on synthetic data, medical events (MIMIC-III), and social media posts (Reddit), comprising 21 total prediction tasks.