 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptNet 5.5: An Open Multilingual Graph of General Knowledge
Dec 12, 2016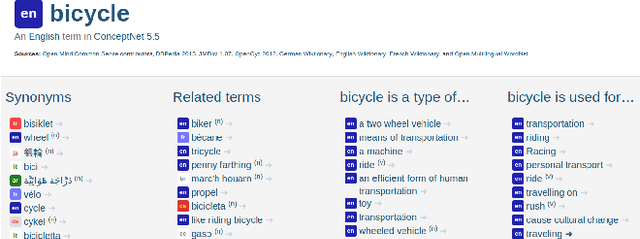

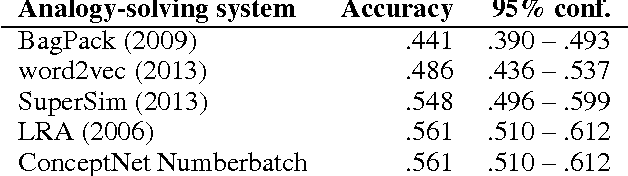
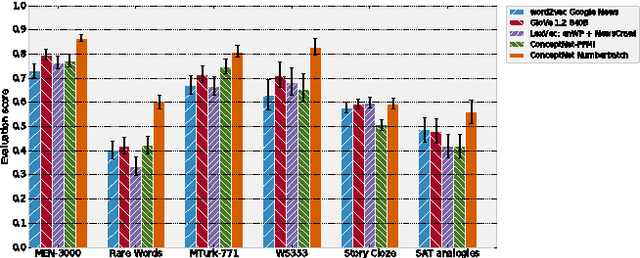
Machine learning about language can be improved by supplying it with specific knowledge and sources of external information. We present here a new version of the linked open data resource ConceptNet that is particularly well suited to be used with modern NLP techniques such as word embeddings. ConceptNet is a knowledge graph that connects words and phrases of natural language with labeled edges. Its knowledge is collected from many sources that include expert-created resources, crowd-sourcing, and games with a purpose. It is designed to represent the general knowledge involved in understanding language, improving natural language applications by allowing the application to better understand the meanings behind the words people use. When ConceptNet is combined with word embeddings acquired from distributional semantics (such as word2vec), it provides applications with understanding that they would not acquire from distributional semantics alone, nor from narrower resources such as WordNet or DBPedia. We demonstrate this with state-of-the-art results on intrinsic evaluations of word relatedness that translate into improvements on applications of word vectors, including solving SAT-style analogies.
An Ensemble Method to Produce High-Quality Word Embeddings
Apr 06, 2016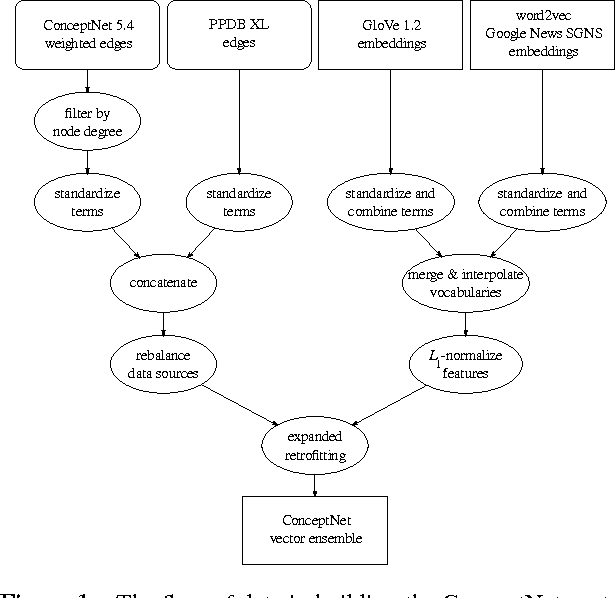
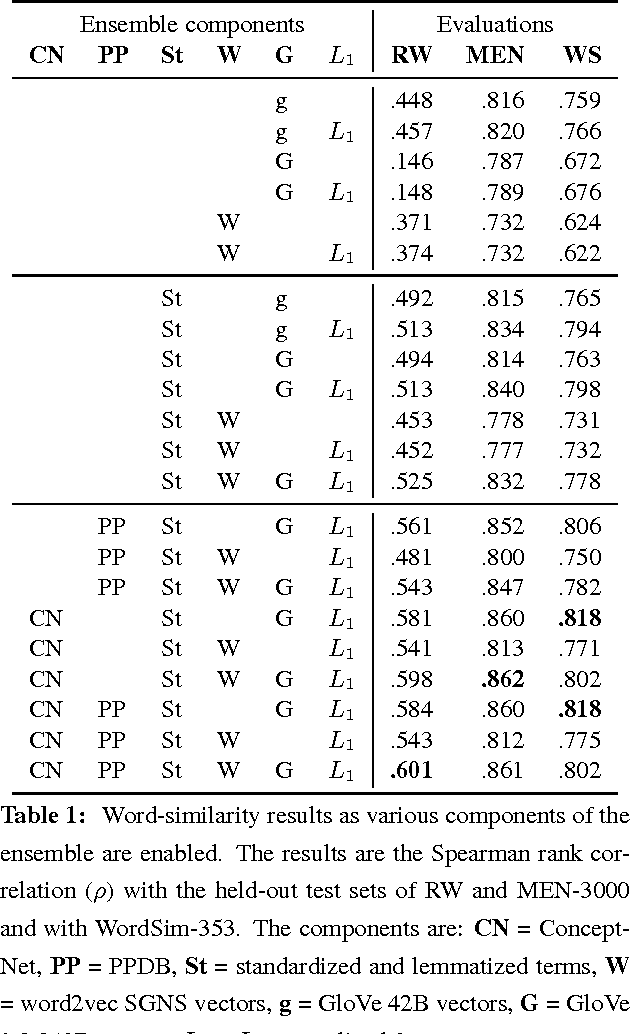
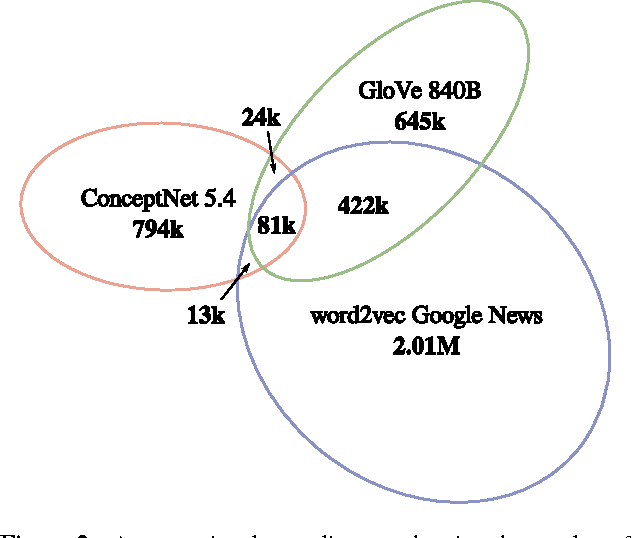
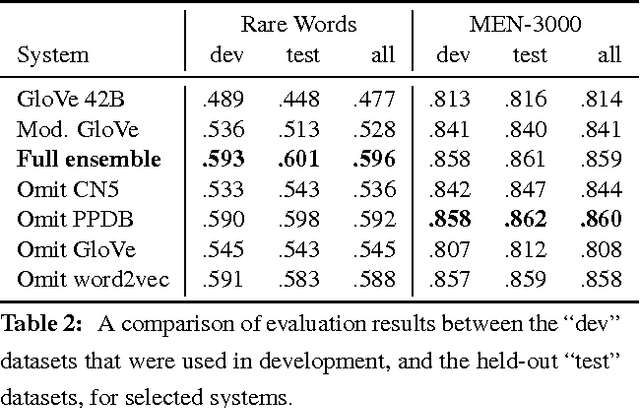
A currently successful approach to computational semantics is to represent words as embeddings in a machine-learned vector space. We present an ensemble method that combines embeddings produced by GloVe (Pennington et al., 2014) and word2vec (Mikolov et al., 2013) with structured knowledge from the semantic networks ConceptNet (Speer and Havasi, 2012) and PPDB (Ganitkevitch et al., 2013), merging their information into a common representation with a large, multilingual vocabulary. The embeddings it produces achieve state-of-the-art performance on many word-similarity evaluations. Its score of $\rho = .596$ on an evaluation of rare words (Luong et al., 2013) is 16% higher than the previous best known system.