Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ensemble Method to Produce High-Quality Word Embeddings
Paper and Code
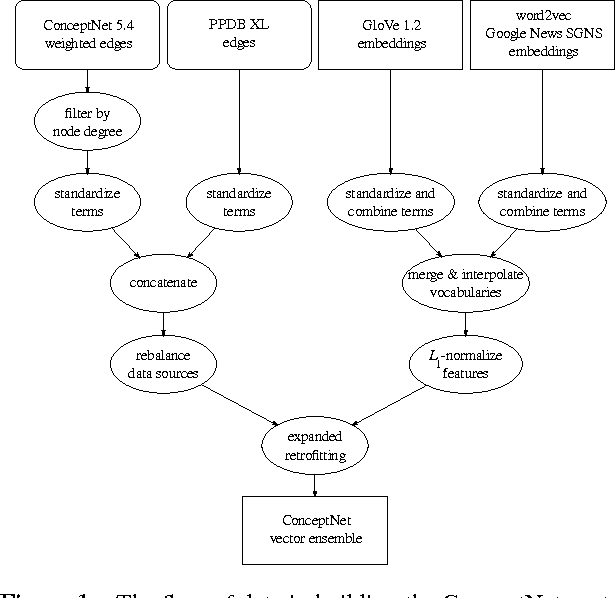
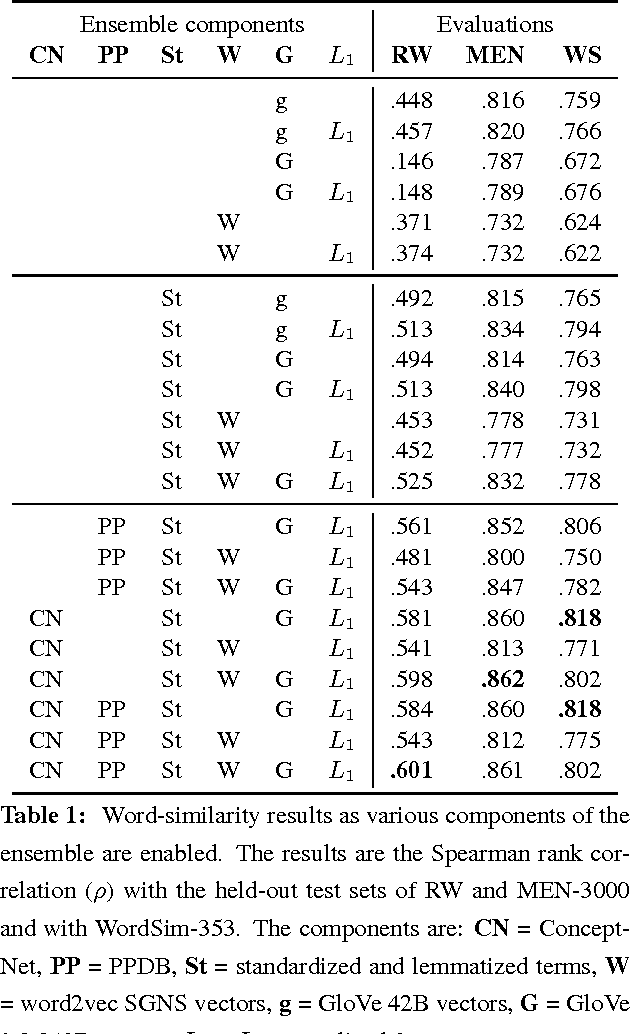
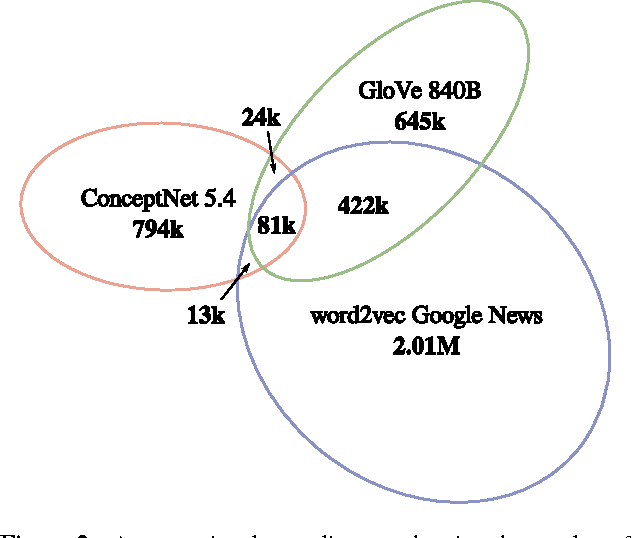
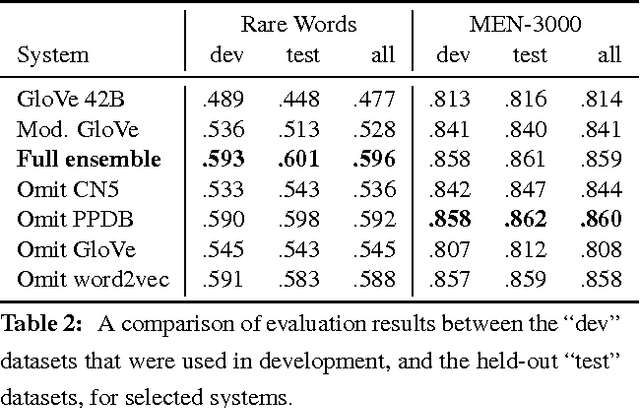
A currently successful approach to computational semantics is to represent words as embeddings in a machine-learned vector space. We present an ensemble method that combines embeddings produced by GloVe (Pennington et al., 2014) and word2vec (Mikolov et al., 2013) with structured knowledge from the semantic networks ConceptNet (Speer and Havasi, 2012) and PPDB (Ganitkevitch et al., 2013), merging their information into a common representation with a large, multilingual vocabulary. The embeddings it produces achieve state-of-the-art performance on many word-similarity evaluations. Its score of $\rho = .596$ on an evaluation of rare words (Luong et al., 2013) is 16% higher than the previous best known system.
* 12 pages, 3 figures
View paper on