 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Polynomial-Based Approach for Architectural Design and Learning with Deep Neural Networks
May 28, 2019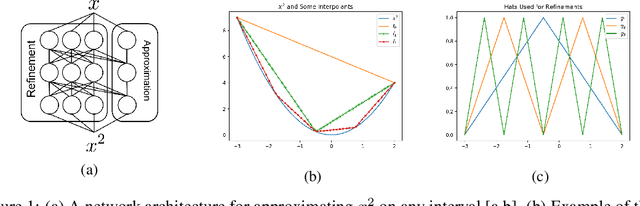
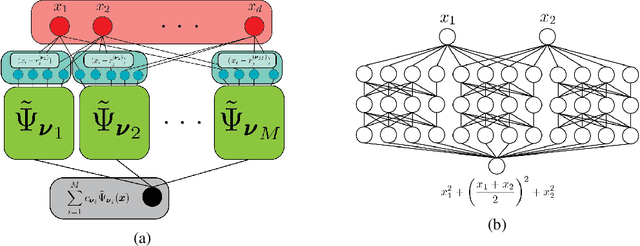
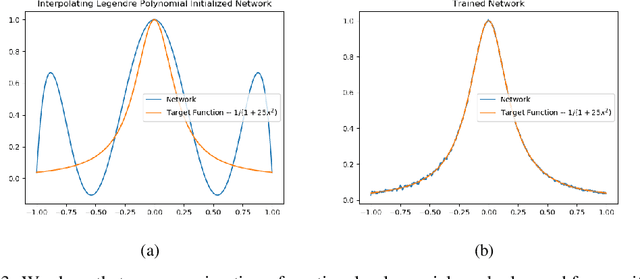
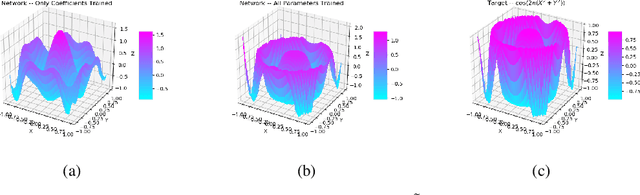
In this effort we propose a novel approach for reconstructing multivariate functions from training data, by identifying both a suitable network architecture and an initialization using polynomial-based approximations. Training deep neural networks using gradient descent can be interpreted as moving the set of network parameters along the loss landscape in order to minimize the loss functional. The initialization of parameters is important for iterative training methods based on descent. Our procedure produces a network whose initial state is a polynomial representation of the training data. The major advantage of this technique is from this initialized state the network may be improved using standard training procedures. Since the network already approximates the data, training is more likely to produce a set of parameters associated with a desirable local minimum. We provide the details of the theory necessary for constructing such networks and also consider several numerical examples that reveal our approach ultimately produces networks which can be effectively trained from our initialized state to achieve an improved approximation for a large class of target functions.