 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-Flow-VAE: A Weakly-supervised Model for Multi-Label Text Classification
Oct 27, 2022
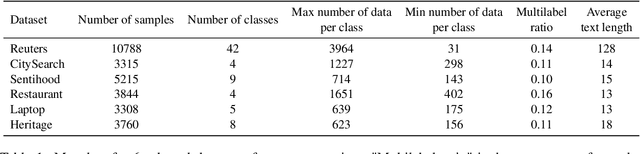

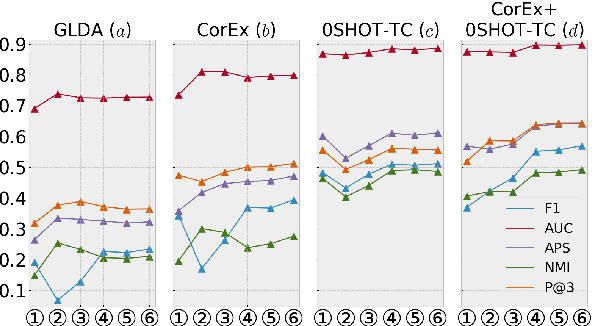
Multi-label Text Classification (MLTC) is the task of categorizing documents into one or more topics. Considering the large volumes of data and varying domains of such tasks, fully supervised learning requires manually fully annotated datasets which is costly and time-consuming. In this paper, we propose BERT-Flow-VAE (BFV), a Weakly-Supervised Multi-Label Text Classification (WSMLTC) model that reduces the need for full supervision. This new model (1) produces BERT sentence embeddings and calibrates them using a flow model, (2) generates an initial topic-document matrix by averaging results of a seeded sparse topic model and a textual entailment model which only require surface name of topics and 4-6 seed words per topic, and (3) adopts a VAE framework to reconstruct the embeddings under the guidance of the topic-document matrix. Finally, (4) it uses the means produced by the encoder model in the VAE architecture as predictions for MLTC. Experimental results on 6 multi-label datasets show that BFV can substantially outperform other baseline WSMLTC models in key metrics and achieve approximately 84% performance of a fully-supervised model.
* 8 pages, 4 figures