 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnealing for Distributed Global Optimization
Mar 18, 2019The paper proves convergence to global optima for a class of distributed algorithms for nonconvex optimization in network-based multi-agent settings. Agents are permitted to communicate over a time-varying undirected graph. Each agent is assumed to possess a local objective function (assumed to be smooth, but possibly nonconvex). The paper considers algorithms for optimizing the sum function. A distributed algorithm of the consensus+innovations type is proposed which relies on first-order information at the agent level. Under appropriate conditions on network connectivity and the cost objective, convergence to the set of global optima is achieved by an annealing-type approach, with decaying Gaussian noise independently added into each agent's update step. It is shown that the proposed algorithm converges in probability to the set of global minima of the sum function.
$QD$-Learning: A Collaborative Distributed Strategy for Multi-Agent Reinforcement Learning Through Consensus + Innovations
Oct 25, 2012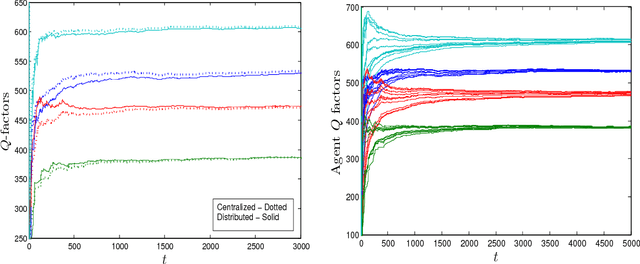
The paper considers a class of multi-agent Markov decision processes (MDPs), in which the network agents respond differently (as manifested by the instantaneous one-stage random costs) to a global controlled state and the control actions of a remote controller. The paper investigates a distributed reinforcement learning setup with no prior information on the global state transition and local agent cost statistics. Specifically, with the agents' objective consisting of minimizing a network-averaged infinite horizon discounted cost, the paper proposes a distributed version of $Q$-learning, $\mathcal{QD}$-learning, in which the network agents collaborate by means of local processing and mutual information exchange over a sparse (possibly stochastic) communication network to achieve the network goal. Under the assumption that each agent is only aware of its local online cost data and the inter-agent communication network is \emph{weakly} connected, the proposed distributed scheme is almost surely (a.s.) shown to yield asymptotically the desired value function and the optimal stationary control policy at each network agent. The analytical techniques developed in the paper to address the mixed time-scale stochastic dynamics of the \emph{consensus + innovations} form, which arise as a result of the proposed interactive distributed scheme, are of independent interest.