 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronoVAE-HOPE: Beyond Attention -- A Next-Generation VAE Foundation Model for Specialized Time Series Classification
May 21, 2026Time Series Foundation Models (TSFMs) have become a new component of the state-of-the-art in general time series forecasting. However, adapting them to specialized classification tasks remains constrained by two interconnected challenges: the quadratic cost of standard attention mechanisms and the inability to disentangle the structural components underlying time series variability. This technical report introduces ChronoVAE-HOPE, a next-generation TSFM that reconciles massive generalization with structured latent representation for time series classification. The core of the proposal is a Variational Autoencoder (VAE) framework built upon the HOPE Block, which replaces quadratic attention with a dual-memory system: Titans modules for dynamic short-term retention and a Continuum Memory System (CMS) for the abstraction of long-term historical context. A key architectural novelty is the disentangled latent space, which factorizes representations into independent trend and seasonal components via dedicated encoder heads and separate decoder pathways. ChronoVAE-HOPE undergoes self-supervised pre-training on the Monash archive, combining a Masked Time Series Modeling (MTSM) auxiliary objective with a disentangled VAE reconstruction loss. The pre-trained encoder is subsequently frozen and used to generate fixed-length embeddings for downstream classification on the UCR benchmark datasets. Empirical results demonstrate strong performance across diverse temporal domains, particularly in settings characterized by strict causal structure. ChronoVAE-HOPE establishes a robust and interpretable framework for the adaptation of foundation models to time series classification through structured generative representations.
KairosHope: A Next-Generation Time-Series Foundation Model for Specialized Classification via Dual-Memory Architecture
May 18, 2026Time Series Foundation Models (TSFMs) have demonstrated notable success in general-purpose forecasting tasks; however, their adaptation to specialized classification problems remains constrained by the computational bottleneck of standard attention and the systematic omission of classical statistical knowledge. This technical report introduces KairosHope, a next-generation TSFM designed to reconcile massive generalization with analytical precision in classification tasks. The core of the proposal is the HOPE block, an architecture that replaces quadratic attention with a dual-memory system: Titans modules for dynamic short-term retention and a Continuum Memory System (CMS) for the abstraction of long-term historical context. To enrich the inductive bias, a Hybrid Decision Head is introduced, which fuses deep latent representations with deterministic statistical features extracted via tsfeatures package. KairosHope undergoes self-supervised pre-training on the massive Monash archive, combining Masked Time Series Modeling (MTSM) and contrastive learning (InfoNCE). Its subsequent adaptation to the UCR benchmark datasets is conducted through a rigorous Linear Probing and Full Fine-Tuning (LP-FT) protocol to prevent catastrophic forgetting. Empirical results demonstrate superior performance in domains characterized by strict temporal causality such as HAR or Sensor data. Consequently, KairosHope establishes a robust and efficient framework for the adaptation of foundation models to time series analysis.
MoEITS: A Green AI approach for simplifying MoE-LLMs
Apr 12, 2026Large language models are transforming all areas of academia and industry, attracting the attention of researchers, professionals, and the general public. In the trek for more powerful architectures, Mixture-of-Experts, inspired by ensemble models, have emerged as one of the most effective ways to follow. However, this implies a high computational burden for both training and inference. To reduce the impact on computing and memory footprint as well as the energy consumption, simplification methods has arisen as very effective procedures. In this paper, an original algorithm, MoEITS, for MoE-LLMs simplification is presented. The algorithm is characterized by a refined simplicity, underpinned by standardized Information Theoretic frameworks. MoEITS is analyzed in depth from theoretical and practical points of view. Its computational complexity is studied. Its performance on the accuracy of the simplified LLMs and the reduction rate achieved is assessed through a thoroughly designed experimentation. This empirical evaluation includes a comparison with state-of-the-art MoE-LLM pruning methods applied on Mixtral $8\times7$B, Qwen1.5-2.7B, and DeepSeek-V2-Lite. The extensive experimentation conducted demonstrates that MoEITS outperforms state-of-the-art techniques by generating models that are both effective across all benchmarks and computationally efficient. The code implementing the method will be available at https://github.com/luisbalru/MoEITS.
Sports center customer segmentation: a case study
May 23, 2024Customer segmentation is a fundamental process to develop effective marketing strategies, personalize customer experience and boost their retention and loyalty. This problem has been widely addressed in the scientific literature, yet no definitive solution for every case is available. A specific case study characterized by several individualizing features is thoroughly analyzed and discussed in this paper. Because of the case properties a robust and innovative approach to both data handling and analytical processes is required. The study led to a sound proposal for customer segmentation. The highlights of the proposal include a convenient data partition to decompose the problem, an adaptive distance function definition and its optimization through genetic algorithms. These comprehensive data handling strategies not only enhance the dataset reliability for segmentation analysis but also support the operational efficiency and marketing strategies of sports centers, ultimately improving the customer experience.
Can persistent homology whiten Transformer-based black-box models? A case study on BERT compression
Dec 17, 2023



Large Language Models (LLMs) like BERT have gained significant prominence due to their remarkable performance in various natural language processing tasks. However, they come with substantial computational and memory costs. Additionally, they are essentially black-box models, challenging to explain and interpret. In this article, we propose Optimus BERT Compression and Explainability (OBCE), a methodology to bring explainability to BERT models using persistent homology, aiming to measure the importance of each neuron by studying the topological characteristics of their outputs. As a result, we can compress BERT significantly by reducing the number of parameters (58.47% of the original parameters for BERT Base, 52.3% for BERT Large). We evaluated our methodology on the standard GLUE Benchmark, comparing the results with state-of-the-art techniques and achieving outstanding results. Consequently, our methodology can "whiten" BERT models by providing explainability to its neurons and reducing the model's size, making it more suitable for deployment on resource-constrained devices.
Optimizing Convolutional Neural Network Architecture
Dec 17, 2023
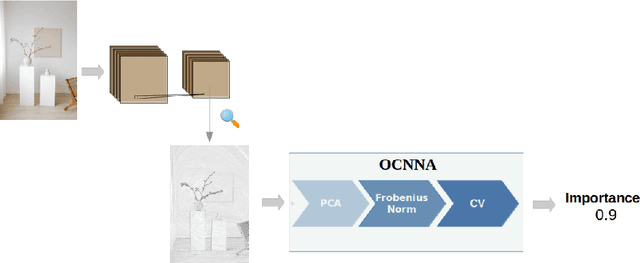


Convolutional Neural Networks (CNN) are widely used to face challenging tasks like speech recognition, natural language processing or computer vision. As CNN architectures get larger and more complex, their computational requirements increase, incurring significant energetic costs and challenging their deployment on resource-restricted devices. In this paper, we propose Optimizing Convolutional Neural Network Architecture (OCNNA), a novel CNN optimization and construction method based on pruning and knowledge distillation designed to establish the importance of convolutional layers. The proposal has been evaluated though a thorough empirical study including the best known datasets (CIFAR-10, CIFAR-100 and Imagenet) and CNN architectures (VGG-16, ResNet-50, DenseNet-40 and MobileNet), setting Accuracy Drop and Remaining Parameters Ratio as objective metrics to compare the performance of OCNNA against the other state-of-art approaches. Our method has been compared with more than 20 convolutional neural network simplification algorithms obtaining outstanding results. As a result, OCNNA is a competitive CNN constructing method which could ease the deployment of neural networks into IoT or resource-limited devices.
Optimizing Dense Feed-Forward Neural Networks
Dec 16, 2023


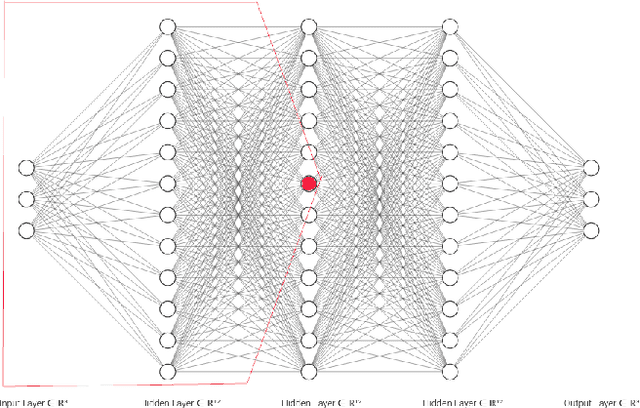
Deep learning models have been widely used during the last decade due to their outstanding learning and abstraction capacities. However, one of the main challenges any scientist has to face using deep learning models is to establish the network's architecture. Due to this difficulty, data scientists usually build over complex models and, as a result, most of them result computationally intensive and impose a large memory footprint, generating huge costs, contributing to climate change and hindering their use in computational-limited devices. In this paper, we propose a novel feed-forward neural network constructing method based on pruning and transfer learning. Its performance has been thoroughly assessed in classification and regression problems. Without any accuracy loss, our approach can compress the number of parameters by more than 70%. Even further, choosing the pruning parameter carefully, most of the refined models outperform original ones. We also evaluate the transfer learning level comparing the refined model and the original one training from scratch a neural network with the same hyper parameters as the optimized model. The results obtained show that our constructing method not only helps in the design of more efficient models but also more effective ones.
Multivariable times series classification through an interpretable representation
Sep 08, 2020


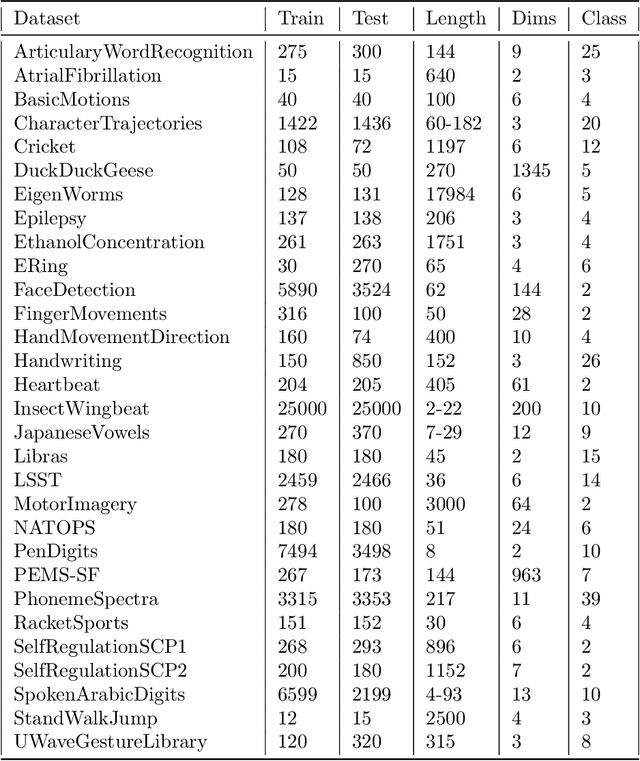
Multivariate time series classification is a task with increasing importance due to the proliferation of new problems in various fields (economy, health, energy, transport, crops, etc.) where a large number of information sources are available. Direct extrapolation of methods that traditionally worked in univariate environments cannot frequently be applied to obtain the best results in multivariate problems. This is mainly due to the inability of these methods to capture the relationships between the different variables that conform a multivariate time series. The multivariate proposals published to date offer competitive results but are hard to interpret. In this paper we propose a time series classification method that considers an alternative representation of time series through a set of descriptive features taking into account the relationships between the different variables of a multivariate time series. We have applied traditional classification algorithms obtaining interpretable and competitive results.
Complexity Measures and Features for Times Series classification
Mar 04, 2020
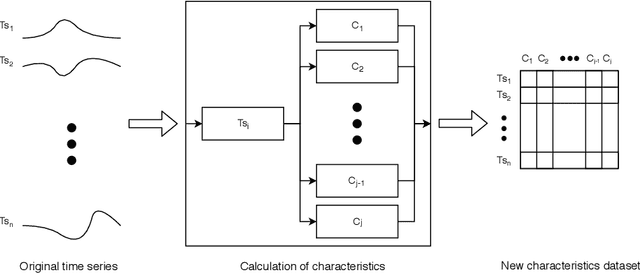
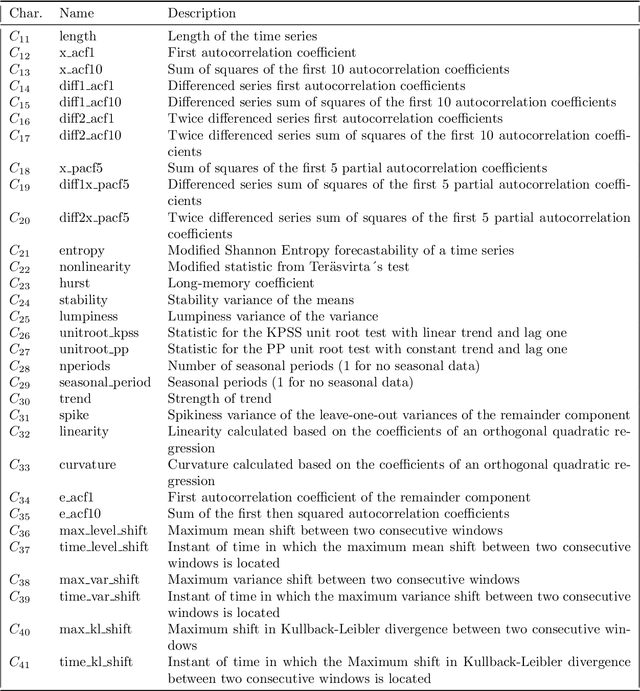
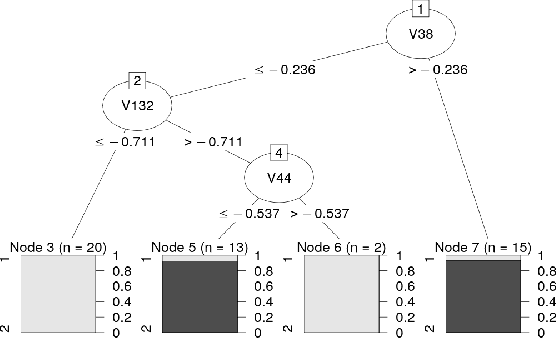
Classification of time series is a growing problem in different disciplines due to the progressive digitalization of the world. Currently, the state of the art in time series classification is dominated by Collective of Transformation-Based Ensembles. This algorithm is composed of several classifiers of diverse nature that are combined according to their results in an internal cross validation procedure. Its high complexity prevents it from being applied to large datasets. One Nearest Neighbours with Dynamic Time Warping remains the base classifier in any time series classification problem, for its simplicity and good results. Despite their good performance, they share a weakness, which is that they are not interpretable. In the field of time series classification, there is a tradeoff between accuracy and interpretability. In this work, we propose a set of characteristics capable of extracting information of the structure of the time series in order to face time series classification problems. The use of these characteristics allows the use of traditional classification algorithms in time series problems. The experimental results demonstrate a statistically significant improvement in the accuracy of the results obtained by our proposal with respect to the original time series. Apart from the improvement in accuracy, our proposal is able to offer interpretable results based on the set of characteristics proposed.