 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Augmentation-based Model Re-adaptation Framework for Robust Image Segmentation
Sep 14, 2024



Image segmentation is a crucial task in computer vision, with wide-ranging applications in industry. The Segment Anything Model (SAM) has recently attracted intensive attention; however, its application in industrial inspection, particularly for segmenting commercial anti-counterfeit codes, remains challenging. Unlike open-source datasets, industrial settings often face issues such as small sample sizes and complex textures. Additionally, computational cost is a key concern due to the varying number of trainable parameters. To address these challenges, we propose an Augmentation-based Model Re-adaptation Framework (AMRF). This framework leverages data augmentation techniques during training to enhance the generalisation of segmentation models, allowing them to adapt to newly released datasets with temporal disparity. By observing segmentation masks from conventional models (FCN and U-Net) and a pre-trained SAM model, we determine a minimal augmentation set that optimally balances training efficiency and model performance. Our results demonstrate that the fine-tuned FCN surpasses its baseline by 3.29% and 3.02% in cropping accuracy, and 5.27% and 4.04% in classification accuracy on two temporally continuous datasets. Similarly, the fine-tuned U-Net improves upon its baseline by 7.34% and 4.94% in cropping, and 8.02% and 5.52% in classification. Both models outperform the top-performing SAM models (ViT-Large and ViT-Base) by an average of 11.75% and 9.01% in cropping accuracy, and 2.93% and 4.83% in classification accuracy, respectively.
Robust and Explainable Fine-Grained Visual Classification with Transfer Learning: A Dual-Carriageway Framework
May 09, 2024In the realm of practical fine-grained visual classification applications rooted in deep learning, a common scenario involves training a model using a pre-existing dataset. Subsequently, a new dataset becomes available, prompting the desire to make a pivotal decision for achieving enhanced and leveraged inference performance on both sides: Should one opt to train datasets from scratch or fine-tune the model trained on the initial dataset using the newly released dataset? The existing literature reveals a lack of methods to systematically determine the optimal training strategy, necessitating explainability. To this end, we present an automatic best-suit training solution searching framework, the Dual-Carriageway Framework (DCF), to fill this gap. DCF benefits from the design of a dual-direction search (starting from the pre-existing or the newly released dataset) where five different training settings are enforced. In addition, DCF is not only capable of figuring out the optimal training strategy with the capability of avoiding overfitting but also yields built-in quantitative and visual explanations derived from the actual input and weights of the trained model. We validated DCF's effectiveness through experiments with three convolutional neural networks (ResNet18, ResNet34 and Inception-v3) on two temporally continued commercial product datasets. Results showed fine-tuning pathways outperformed training-from-scratch ones by up to 2.13% and 1.23% on the pre-existing and new datasets, respectively, in terms of mean accuracy. Furthermore, DCF identified reflection padding as the superior padding method, enhancing testing accuracy by 3.72% on average. This framework stands out for its potential to guide the development of robust and explainable AI solutions in fine-grained visual classification tasks.
How Quality Affects Deep Neural Networks in Fine-Grained Image Classification
May 09, 2024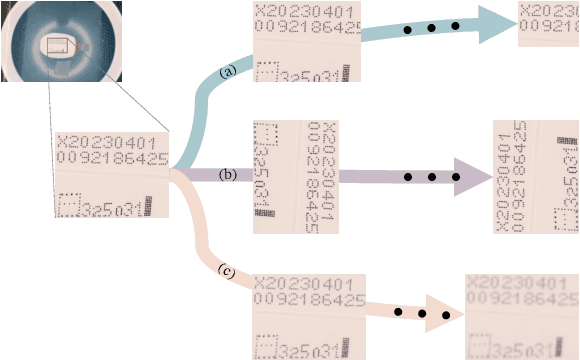
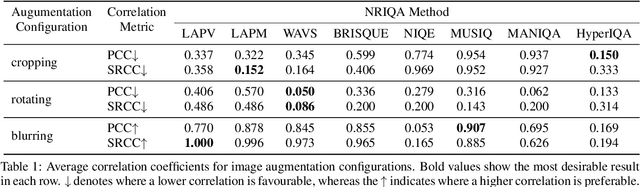
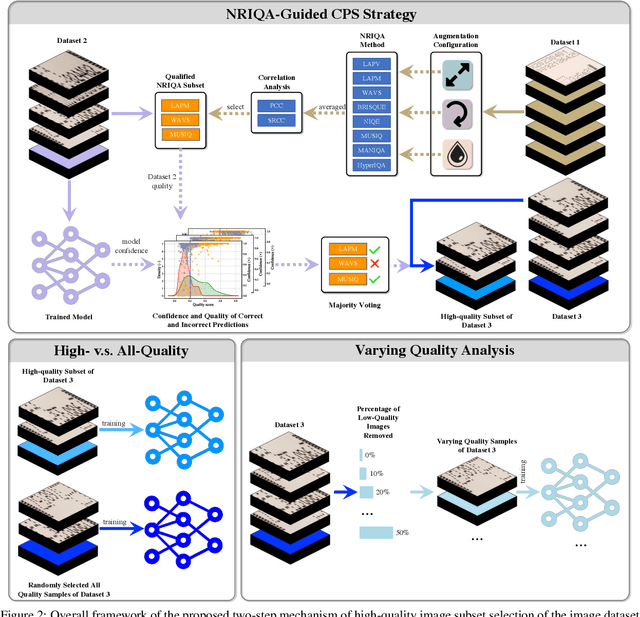
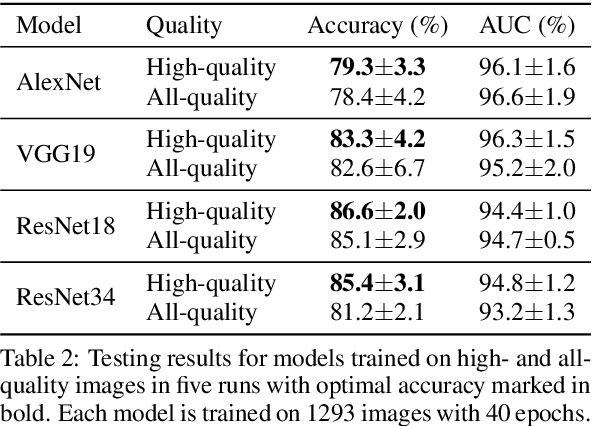
In this paper, we propose a No-Reference Image Quality Assessment (NRIQA) guided cut-off point selection (CPS) strategy to enhance the performance of a fine-grained classification system. Scores given by existing NRIQA methods on the same image may vary and not be as independent of natural image augmentations as expected, which weakens their connection and explainability to fine-grained image classification. Taking the three most commonly adopted image augmentation configurations -- cropping, rotating, and blurring -- as the entry point, we formulate a two-step mechanism for selecting the most discriminative subset from a given image dataset by considering both the confidence of model predictions and the density distribution of image qualities over several NRIQA methods. Concretely, the cut-off points yielded by those methods are aggregated via majority voting to inform the process of image subset selection. The efficacy and efficiency of such a mechanism have been confirmed by comparing the models being trained on high-quality images against a combination of high- and low-quality ones, with a range of 0.7% to 4.2% improvement on a commercial product dataset in terms of mean accuracy through four deep neural classifiers. The robustness of the mechanism has been proven by the observations that all the selected high-quality images can work jointly with 70% low-quality images with 1.3% of classification precision sacrificed when using ResNet34 in an ablation study.