 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Evaluation of Domain Adaptation in Facial Expression Recognition
Jun 29, 2021
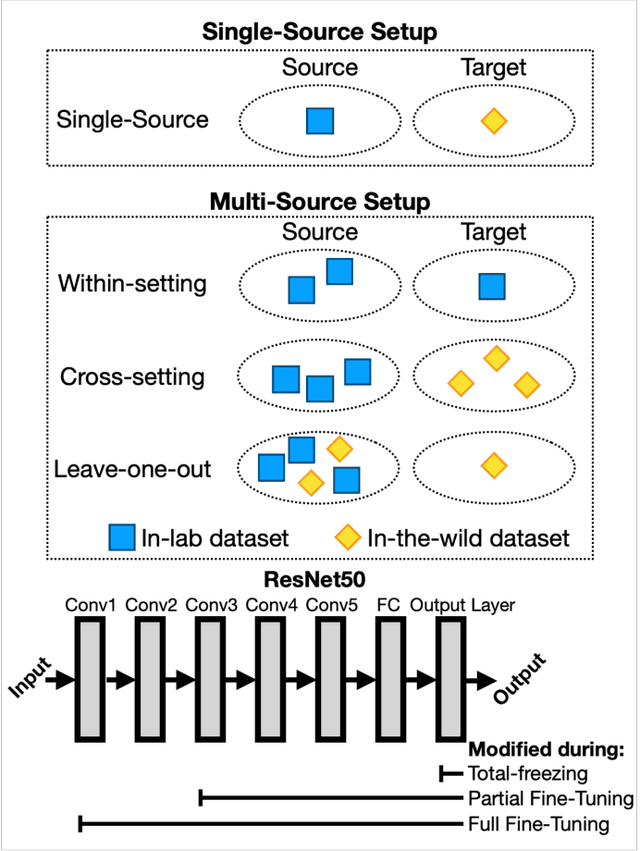

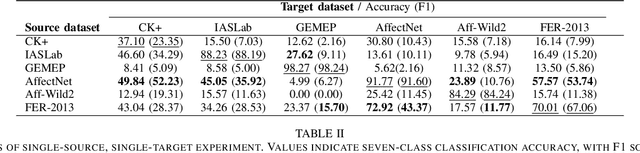
Facial Expression Recognition is a commercially important application, but one common limitation is that applications often require making predictions on out-of-sample distributions, where target images may have very different properties from the images that the model was trained on. How well, or badly, do these models do on unseen target domains? In this paper, we provide a systematic evaluation of domain adaptation in facial expression recognition. Using state-of-the-art transfer learning techniques and six commonly-used facial expression datasets (three collected in the lab and three "in-the-wild"), we conduct extensive round-robin experiments to examine the classification accuracies for a state-of-the-art CNN model. We also perform multi-source experiments where we examine a model's ability to transfer from multiple source datasets, including (i) within-setting (e.g., lab to lab), (ii) cross-setting (e.g., in-the-wild to lab), (iii) mixed-setting (e.g., lab and wild to lab) transfer learning experiments. We find sobering results that the accuracy of transfer learning is not high, and varies idiosyncratically with the target dataset, and to a lesser extent the source dataset. Generally, the best settings for transfer include fine-tuning the weights of a pre-trained model, and we find that training with more datasets, regardless of setting, improves transfer performance. We end with a discussion of the need for more -- and regular -- systematic investigations into the generalizability of FER models, especially for deployed applications.