 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to be fair? A study of label and selection bias
Mar 21, 2024It is widely accepted that biased data leads to biased and thus potentially unfair models. Therefore, several measures for bias in data and model predictions have been proposed, as well as bias mitigation techniques whose aim is to learn models that are fair by design. Despite the myriad of mitigation techniques developed in the past decade, however, it is still poorly understood under what circumstances which methods work. Recently, Wick et al. showed, with experiments on synthetic data, that there exist situations in which bias mitigation techniques lead to more accurate models when measured on unbiased data. Nevertheless, in the absence of a thorough mathematical analysis, it remains unclear which techniques are effective under what circumstances. We propose to address this problem by establishing relationships between the type of bias and the effectiveness of a mitigation technique, where we categorize the mitigation techniques by the bias measure they optimize. In this paper we illustrate this principle for label and selection bias on the one hand, and demographic parity and ``We're All Equal'' on the other hand. Our theoretical analysis allows to explain the results of Wick et al. and we also show that there are situations where minimizing fairness measures does not result in the fairest possible distribution.
Sentiment Analysis for Open Domain Conversational Agent
Jan 03, 2021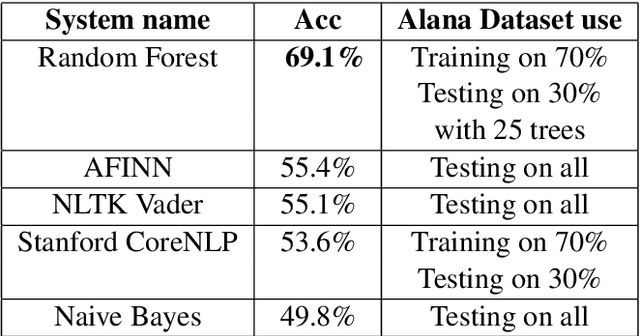
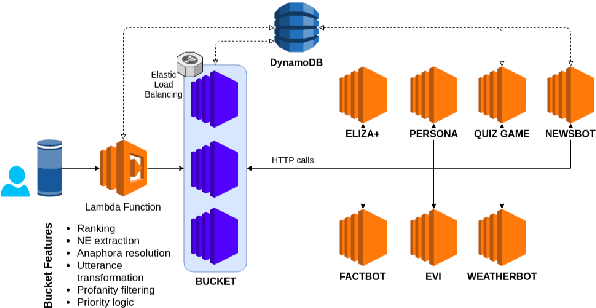
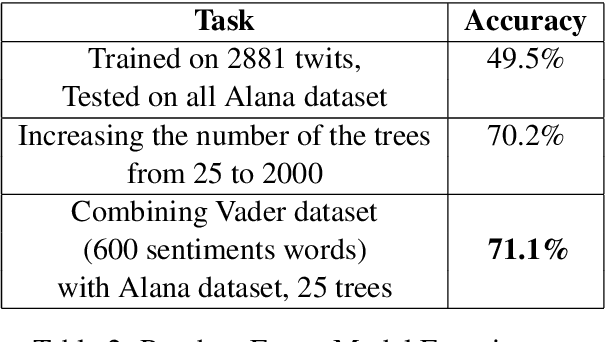
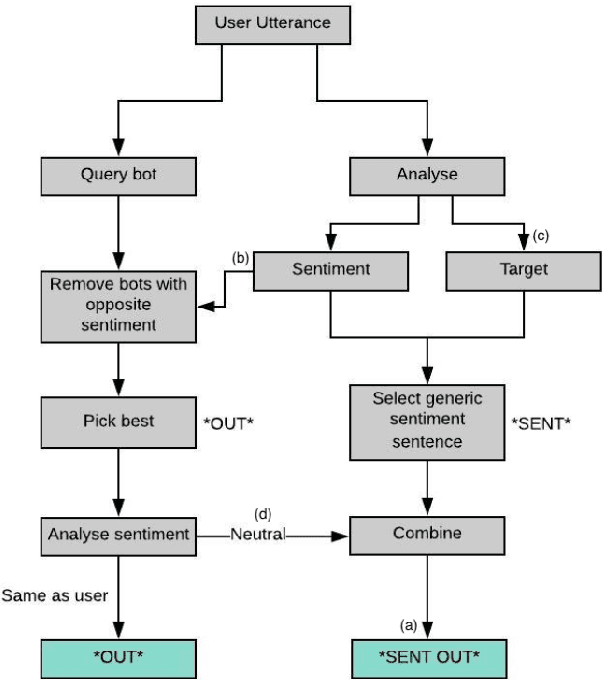
The applicability of common sentiment analysis models to open domain human robot interaction is investigated within this paper. The models are used on a dataset specific to user interaction with the Alana system (a Alexa prize system) in order to determine which would be more appropriate for the task of identifying sentiment when a user interacts with a non-human driven socialbot. With the identification of a model, various improvements are attempted and detailed prior to integration into the Alana system. The study showed that a Random Forest Model with 25 trees trained on the dataset specific to user interaction with the Alana system combined with the dataset present in NLTK Vader outperforms other models. The new system (called 'Rob') matches it's output utterance sentiment with the user's utterance sentiment. This method is expected to improve user experience because it builds upon the overall sentiment detection which makes it seem that new system sympathises with user feelings. Furthermore, the results obtained from the user feedback confirms our expectation.