 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Poisson convolution model for characterizing topical content with word frequency and exclusivity
Jul 28, 2014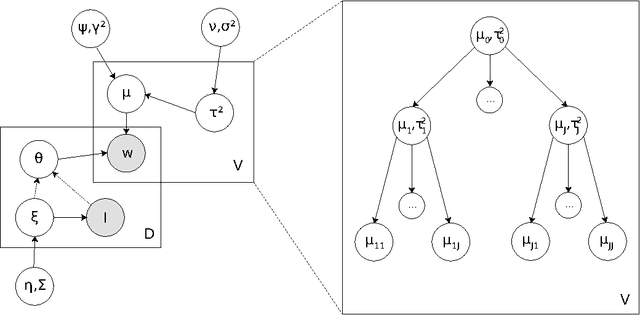
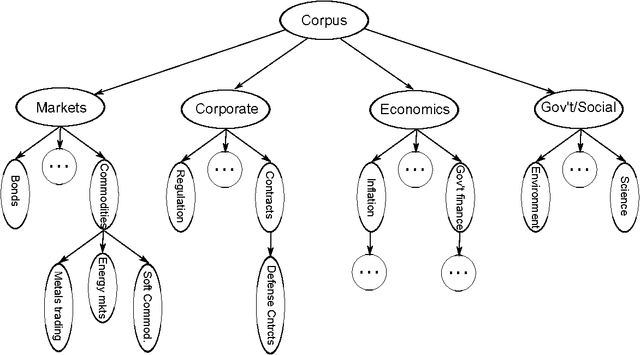
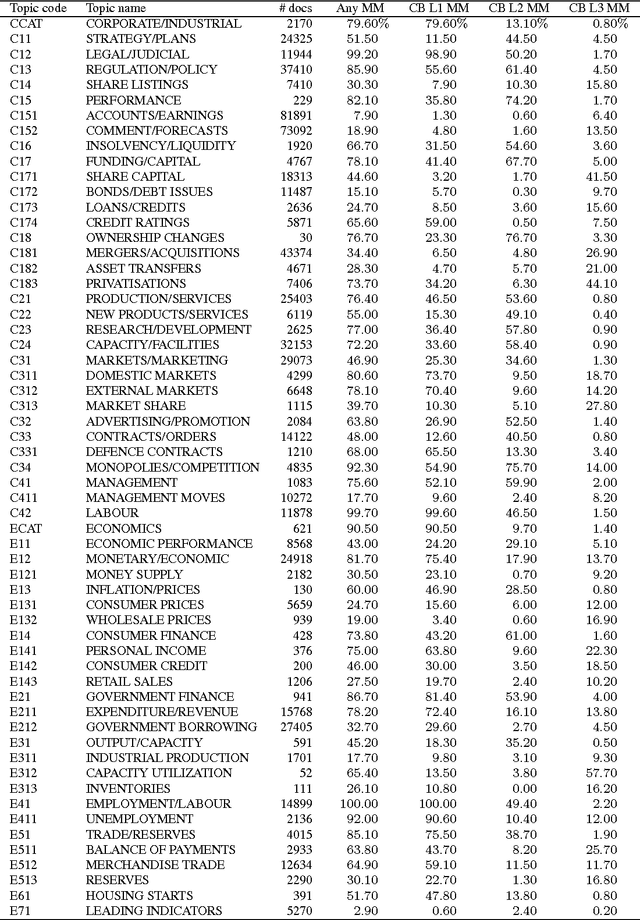
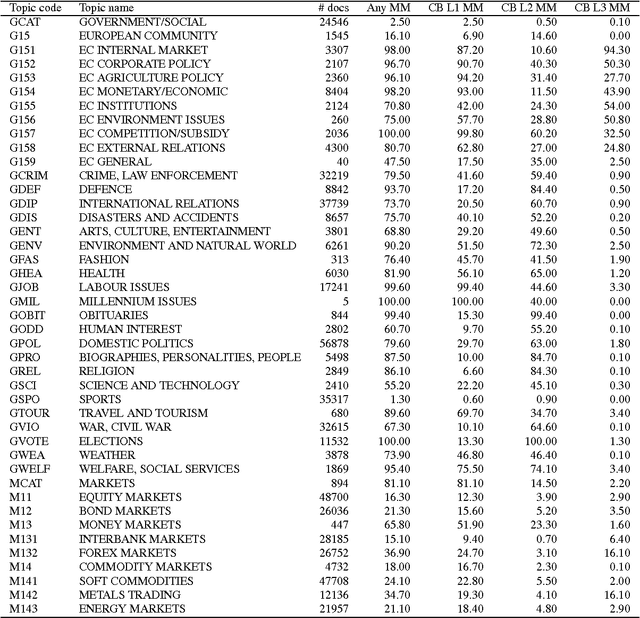
An ongoing challenge in the analysis of document collections is how to summarize content in terms of a set of inferred themes that can be interpreted substantively in terms of topics. The current practice of parametrizing the themes in terms of most frequent words limits interpretability by ignoring the differential use of words across topics. We argue that words that are both common and exclusive to a theme are more effective at characterizing topical content. We consider a setting where professional editors have annotated documents to a collection of topic categories, organized into a tree, in which leaf-nodes correspond to the most specific topics. Each document is annotated to multiple categories, at different levels of the tree. We introduce a hierarchical Poisson convolution model to analyze annotated documents in this setting. The model leverages the structure among categories defined by professional editors to infer a clear semantic description for each topic in terms of words that are both frequent and exclusive. We carry out a large randomized experiment on Amazon Turk to demonstrate that topic summaries based on the FREX score are more interpretable than currently established frequency based summaries, and that the proposed model produces more efficient estimates of exclusivity than with currently models. We also develop a parallelized Hamiltonian Monte Carlo sampler that allows the inference to scale to millions of documents.