 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgetSPM+; a high-performance algorithm for mining transitive sequential patterns from clinical data
Sep 08, 2023
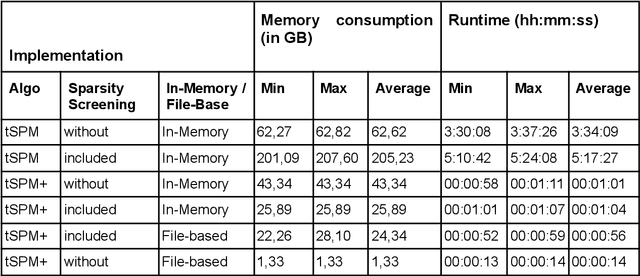
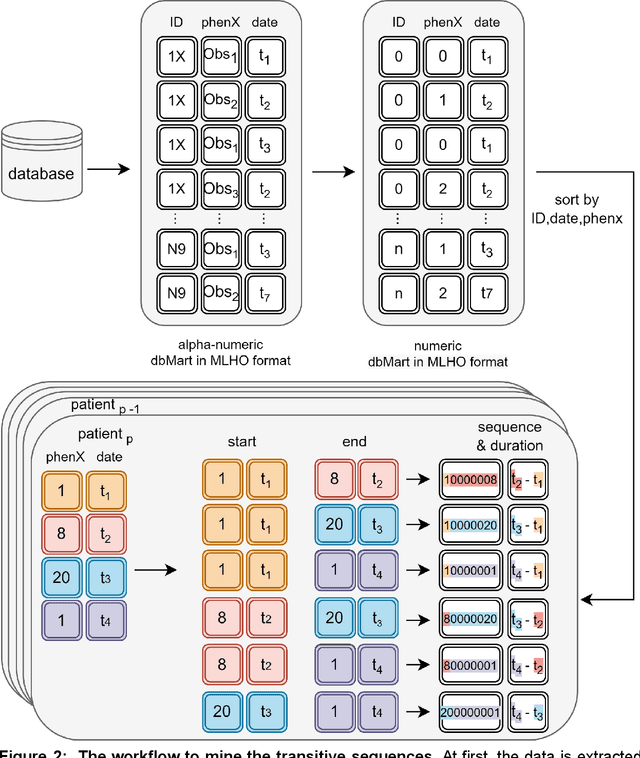
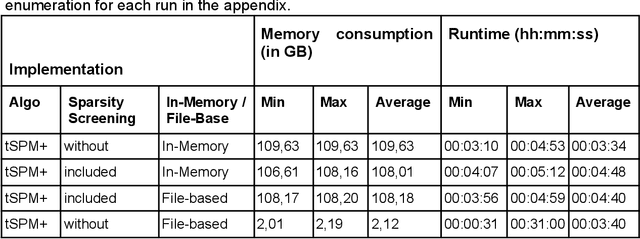
The increasing availability of large clinical datasets collected from patients can enable new avenues for computational characterization of complex diseases using different analytic algorithms. One of the promising new methods for extracting knowledge from large clinical datasets involves temporal pattern mining integrated with machine learning workflows. However, mining these temporal patterns is a computational intensive task and has memory repercussions. Current algorithms, such as the temporal sequence pattern mining (tSPM) algorithm, are already providing promising outcomes, but still leave room for optimization. In this paper, we present the tSPM+ algorithm, a high-performance implementation of the tSPM algorithm, which adds a new dimension by adding the duration to the temporal patterns. We show that the tSPM+ algorithm provides a speed up to factor 980 and a up to 48 fold improvement in memory consumption. Moreover, we present a docker container with an R-package, We also provide vignettes for an easy integration into already existing machine learning workflows and use the mined temporal sequences to identify Post COVID-19 patients and their symptoms according to the WHO definition.
Improving ICD-based semantic similarity by accounting for varying degrees of comorbidity
Aug 14, 2023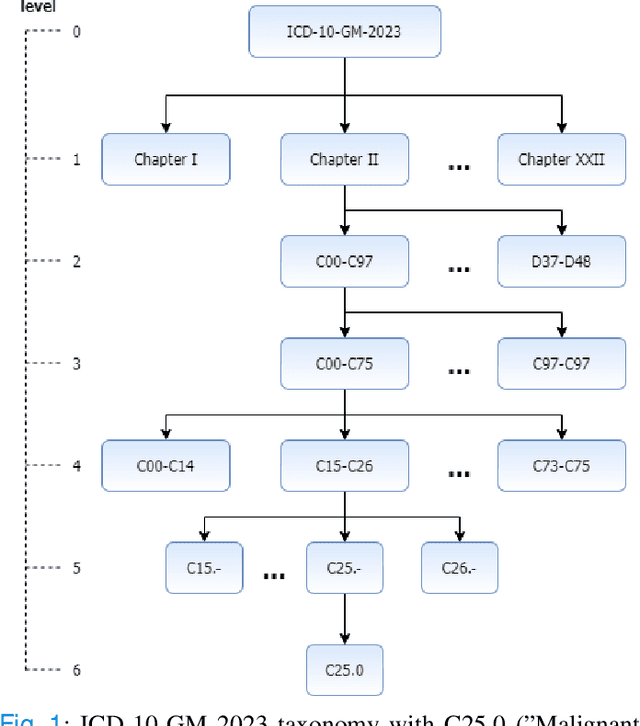
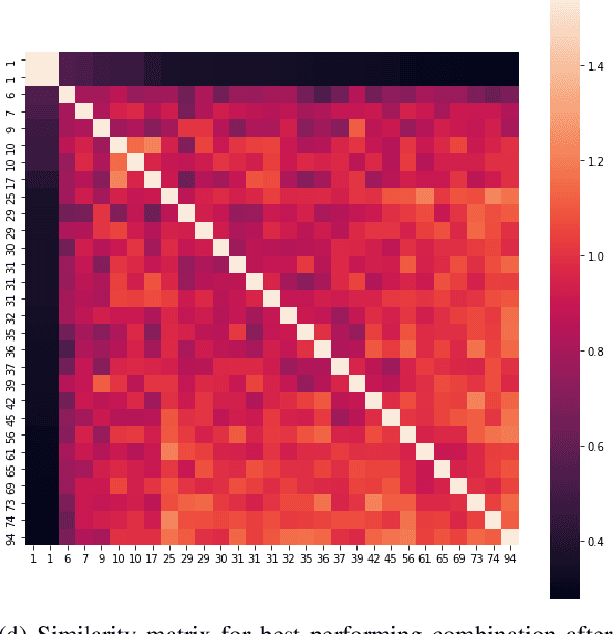
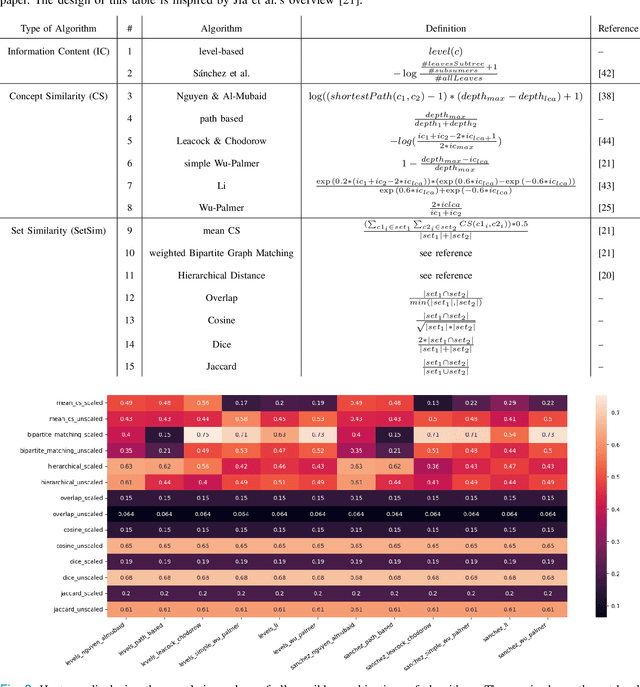
Finding similar patients is a common objective in precision medicine, facilitating treatment outcome assessment and clinical decision support. Choosing widely-available patient features and appropriate mathematical methods for similarity calculations is crucial. International Statistical Classification of Diseases and Related Health Problems (ICD) codes are used worldwide to encode diseases and are available for nearly all patients. Aggregated as sets consisting of primary and secondary diagnoses they can display a degree of comorbidity and reveal comorbidity patterns. It is possible to compute the similarity of patients based on their ICD codes by using semantic similarity algorithms. These algorithms have been traditionally evaluated using a single-term expert rated data set. However, real-word patient data often display varying degrees of documented comorbidities that might impair algorithm performance. To account for this, we present a scale term that considers documented comorbidity-variance. In this work, we compared the performance of 80 combinations of established algorithms in terms of semantic similarity based on ICD-code sets. The sets have been extracted from patients with a C25.X (pancreatic cancer) primary diagnosis and provide a variety of different combinations of ICD-codes. Using our scale term we yielded the best results with a combination of level-based information content, Leacock & Chodorow concept similarity and bipartite graph matching for the set similarities reaching a correlation of 0.75 with our expert's ground truth. Our results highlight the importance of accounting for comorbidity variance while demonstrating how well current semantic similarity algorithms perform.