 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Mode Exploration in Bayesian Model Averaging for Neural Networks
Dec 07, 2021



Multiple techniques for producing calibrated predictive probabilities using deep neural networks in supervised learning settings have emerged that leverage approaches to ensemble diverse solutions discovered during cyclic training or training from multiple random starting points (deep ensembles). However, only a limited amount of work has investigated the utility of exploring the local region around each diverse solution (posterior mode). Using three well-known deep architectures on the CIFAR-10 dataset, we evaluate several simple methods for exploring local regions of the weight space with respect to Brier score, accuracy, and expected calibration error. We consider both Bayesian inference techniques (variational inference and Hamiltonian Monte Carlo applied to the softmax output layer) as well as utilizing the stochastic gradient descent trajectory near optima. While adding separate modes to the ensemble uniformly improves performance, we show that the simple mode exploration methods considered here produce little to no improvement over ensembles without mode exploration.
Randomized Approximation of the Gram Matrix: Exact Computation and Probabilistic Bounds
May 15, 2014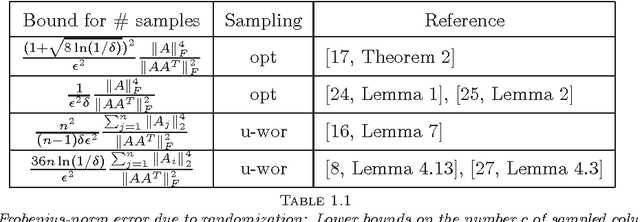
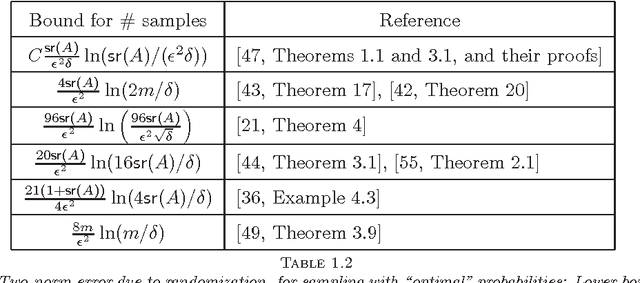
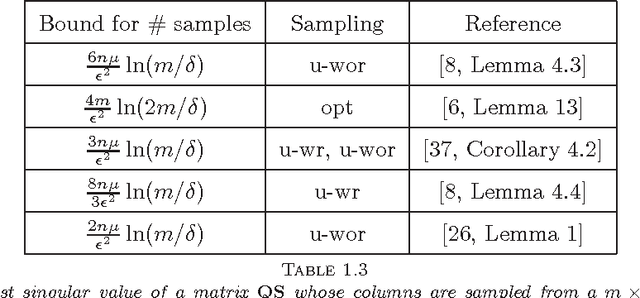
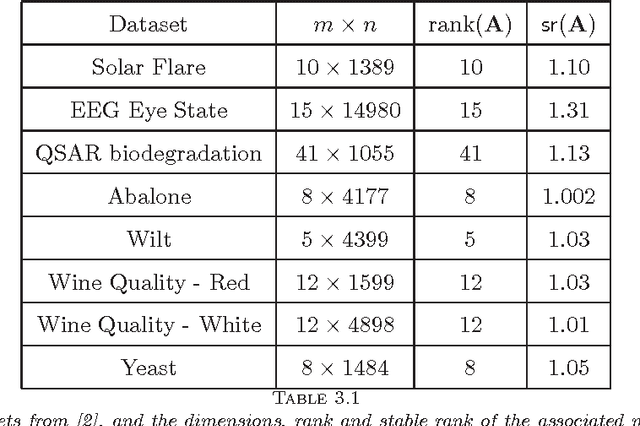
Given a real matrix A with n columns, the problem is to approximate the Gram product AA^T by c << n weighted outer products of columns of A. Necessary and sufficient conditions for the exact computation of AA^T (in exact arithmetic) from c >= rank(A) columns depend on the right singular vector matrix of A. For a Monte-Carlo matrix multiplication algorithm by Drineas et al. that samples outer products, we present probabilistic bounds for the 2-norm relative error due to randomization. The bounds depend on the stable rank or the rank of A, but not on the matrix dimensions. Numerical experiments illustrate that the bounds are informative, even for stringent success probabilities and matrices of small dimension. We also derive bounds for the smallest singular value and the condition number of matrices obtained by sampling rows from orthonormal matrices.