 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning models for representing out-of-vocabulary words
Jul 28, 2020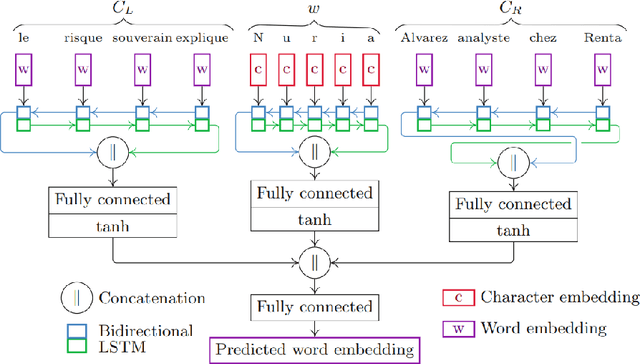
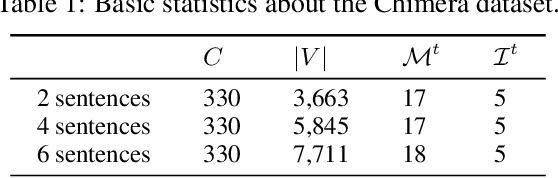
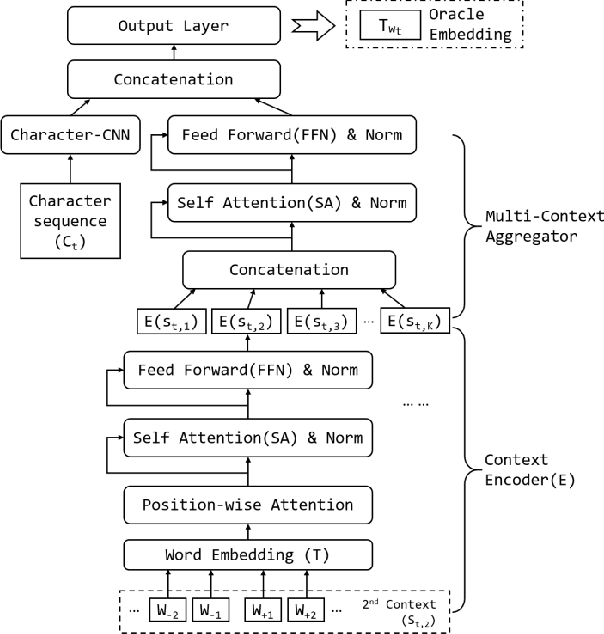
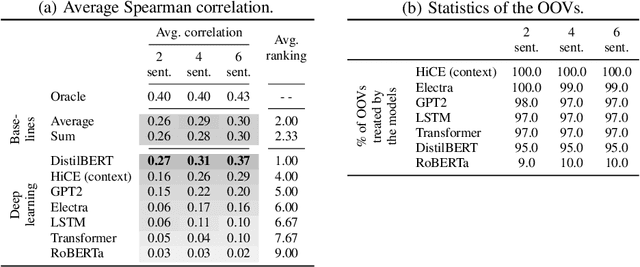
Communication has become increasingly dynamic with the popularization of social networks and applications that allow people to express themselves and communicate instantly. In this scenario, distributed representation models have their quality impacted by new words that appear frequently or that are derived from spelling errors. These words that are unknown by the models, known as out-of-vocabulary (OOV) words, need to be properly handled to not degrade the quality of the natural language processing (NLP) applications, which depend on the appropriate vector representation of the texts. To better understand this problem and finding the best techniques to handle OOV words, in this study, we present a comprehensive performance evaluation of deep learning models for representing OOV words. We performed an intrinsic evaluation using a benchmark dataset and an extrinsic evaluation using different NLP tasks: text categorization, named entity recognition, and part-of-speech tagging. Although the results indicated that the best technique for handling OOV words is different for each task, Comick, a deep learning method that infers the embedding based on the context and the morphological structure of the OOV word, obtained promising results.