 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit card fraud detection using machine learning: A survey
Oct 13, 2020
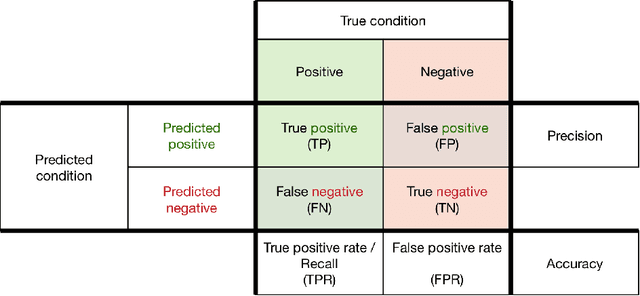
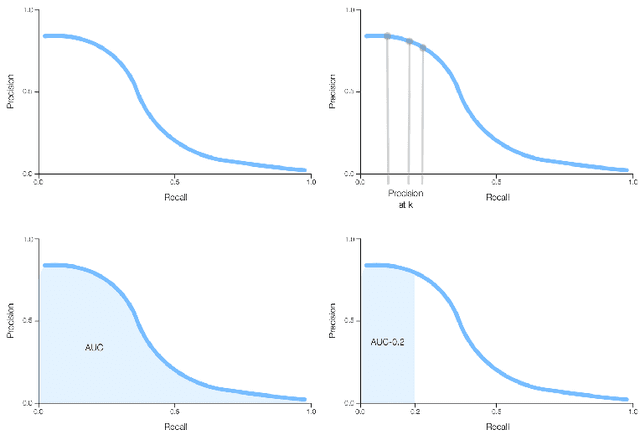
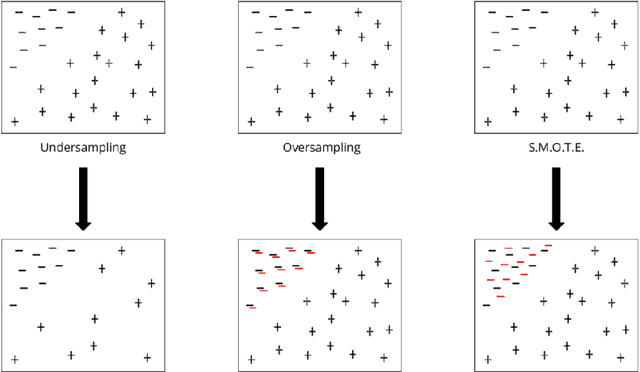
Credit card fraud has emerged as major problem in the electronic payment sector. In this survey, we study data-driven credit card fraud detection particularities and several machine learning methods to address each of its intricate challenges with the goal to identify fraudulent transactions that have been issued illegitimately on behalf of the rightful card owner. In particular, we first characterize a typical credit card detection task: the dataset and its attributes, the metric choice along with some methods to handle such unbalanced datasets. These questions are the entry point of every credit card fraud detection problem. Then we focus on dataset shift (sometimes called concept drift), which refers to the fact that the underlying distribution generating the dataset evolves over times: For example, card holders may change their buying habits over seasons and fraudsters may adapt their strategies. This phenomenon may hinder the usage of machine learning methods for real world datasets such as credit card transactions datasets. Afterwards we highlights different approaches used in order to capture the sequential properties of credit card transactions. These approaches range from feature engineering techniques (transactions aggregations for example) to proper sequence modeling methods such as recurrent neural networks (LSTM) or graphical models (hidden markov models).