 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Named Entity Recognition for Historic German
Jun 18, 2019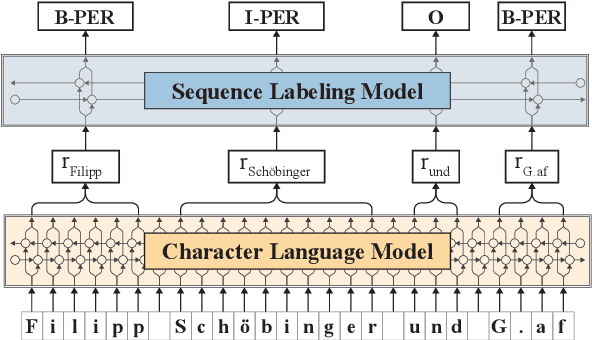
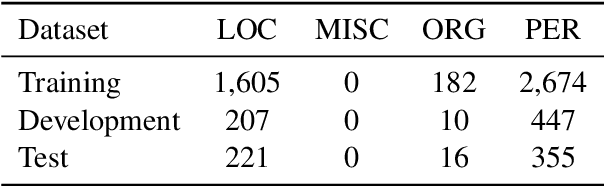
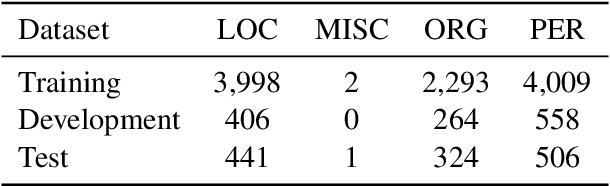
Recent advances in language modeling using deep neural networks have shown that these models learn representations, that vary with the network depth from morphology to semantic relationships like co-reference. We apply pre-trained language models to low-resource named entity recognition for Historic German. We show on a series of experiments that character-based pre-trained language models do not run into trouble when faced with low-resource datasets. Our pre-trained character-based language models improve upon classical CRF-based methods and previous work on Bi-LSTMs by boosting F1 score performance by up to 6%. Our pre-trained language and NER models are publicly available under https://github.com/stefan-it/historic-ner .
Ground Truth for training OCR engines on historical documents in German Fraktur and Early Modern Latin
Sep 14, 2018


In this paper we describe a dataset of German and Latin \textit{ground truth} (GT) for historical OCR in the form of printed text line images paired with their transcription. This dataset, called \textit{GT4HistOCR}, consists of 313,173 line pairs covering a wide period of printing dates from incunabula from the 15th century to 19th century books printed in Fraktur types and is openly available under a CC-BY 4.0 license. The special form of GT as line image/transcription pairs makes it directly usable to train state-of-the-art recognition models for OCR software employing recurring neural networks in LSTM architecture such as Tesseract 4 or OCRopus. We also provide some pretrained OCRopus models for subcorpora of our dataset yielding between 95\% (early printings) and 98\% (19th century Fraktur printings) character accuracy rates on unseen test cases, a Perl script to harmonize GT produced by different transcription rules, and give hints on how to construct GT for OCR purposes which has requirements that may differ from linguistically motivated transcriptions.