 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn analysis on the effects of speaker embedding choice in non auto-regressive TTS
Jul 19, 2023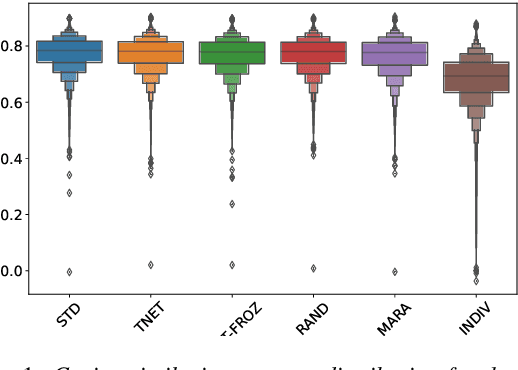

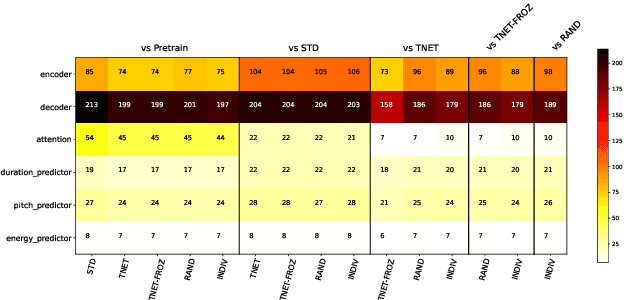
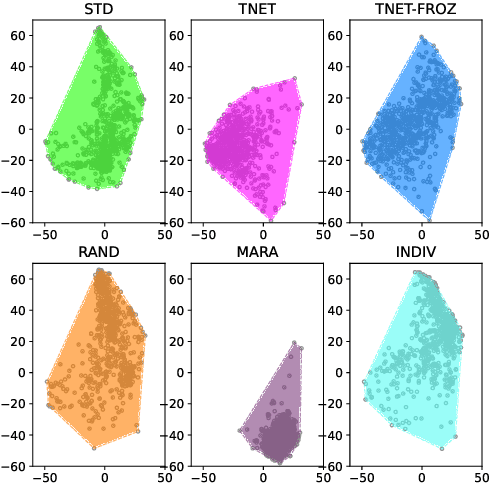
In this paper we introduce a first attempt on understanding how a non-autoregressive factorised multi-speaker speech synthesis architecture exploits the information present in different speaker embedding sets. We analyse if jointly learning the representations, and initialising them from pretrained models determine any quality improvements for target speaker identities. In a separate analysis, we investigate how the different sets of embeddings impact the network's core speech abstraction (i.e. zero conditioned) in terms of speaker identity and representation learning. We show that, regardless of the used set of embeddings and learning strategy, the network can handle various speaker identities equally well, with barely noticeable variations in speech output quality, and that speaker leakage within the core structure of the synthesis system is inevitable in the standard training procedures adopted thus far.
What does BERT learn about prosody?
Apr 25, 2023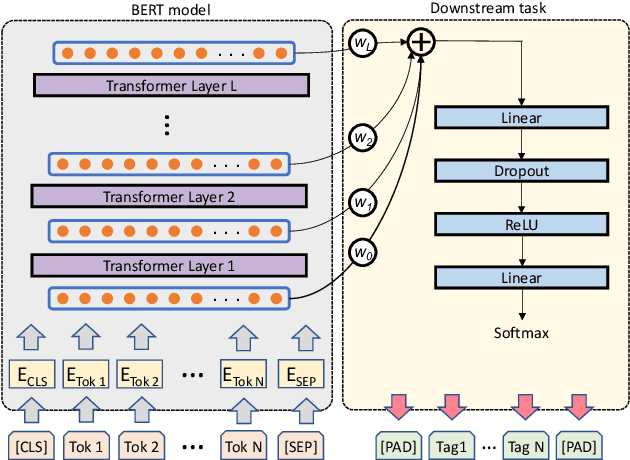
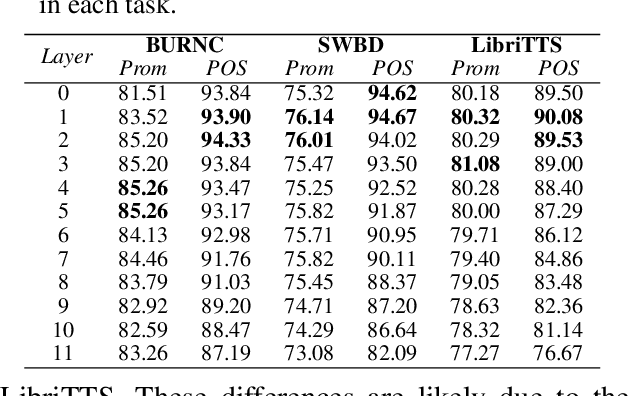
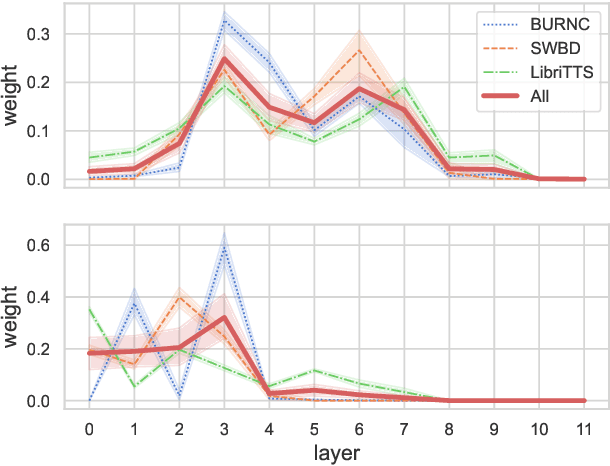

Language models have become nearly ubiquitous in natural language processing applications achieving state-of-the-art results in many tasks including prosody. As the model design does not define predetermined linguistic targets during training but rather aims at learning generalized representations of the language, analyzing and interpreting the representations that models implicitly capture is important in bridging the gap between interpretability and model performance. Several studies have explored the linguistic information that models capture providing some insights on their representational capacity. However, the current studies have not explored whether prosody is part of the structural information of the language that models learn. In this work, we perform a series of experiments on BERT probing the representations captured at different layers. Our results show that information about prosodic prominence spans across many layers but is mostly focused in middle layers suggesting that BERT relies mostly on syntactic and semantic information.