 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Quantization on the Multiple-Round Secret-Key Capacity
May 06, 2021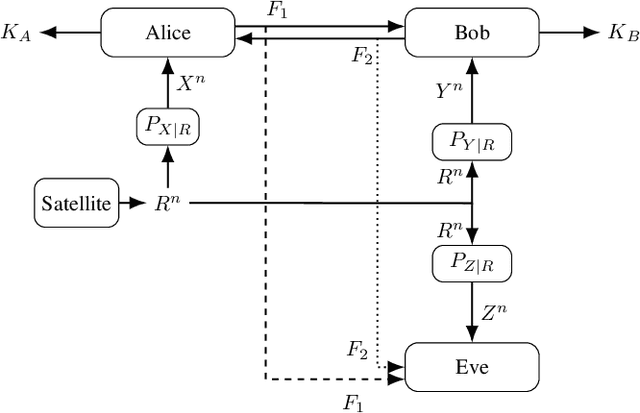
We consider the strong secret key (SK) agreement problem for the satellite communication setting, where a remote source (a satellite) chooses a common binary phase shift keying (BPSK) modulated input for three statistically independent additive white Gaussian noise (AWGN) channels whose outputs are observed by, respectively, two legitimate receivers (Alice and Bob) and an eavesdropper (Eve). Legitimate receivers have access to an authenticated, noiseless, two-way, and public communication link, so they can exchange multiple rounds of public messages to agree on a SK hidden from Eve. Without loss of essential generality, the noise variances for Alice's and Bob's measurement channels are both fixed to a value $Q>1$, whereas the noise over Eve's measurement channel has a unit variance, so $Q$ represents a channel quality ratio. The significant and not necessarily expected effect of quantizations at all receivers on the scaling of the SK capacity with respect to a sufficiently large and finite channel quality ratio $Q$ is illustrated by showing 1) the achievability of a constant SK for any finite BPSK modulated satellite output by proposing a thresholding algorithm as an advantage distillation protocol for AWGN channels and 2) the converse (i.e., unachievability) bound for the case when all receivers apply a one-bit uniform quantizer to their noisy observations before SK agreement, for which the SK capacity is shown to decrease quadratically in $Q$. Our results prove that soft information increases not only the reliability and the achieved SK rate but also the scaling of the SK capacity at least quadratically in $Q$ as compared to hard information.
Multi-task Learning and Catastrophic Forgetting in Continual Reinforcement Learning
Sep 22, 2019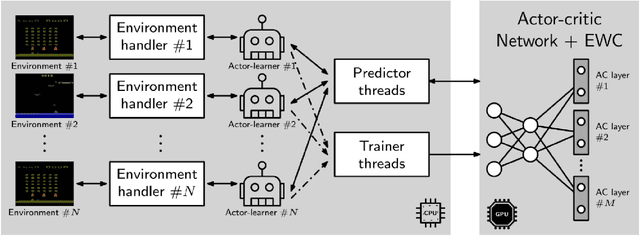


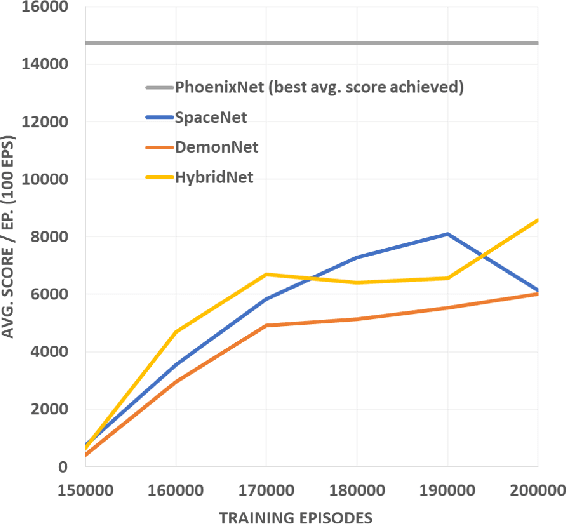
In this paper we investigate two hypothesis regarding the use of deep reinforcement learning in multiple tasks. The first hypothesis is driven by the question of whether a deep reinforcement learning algorithm, trained on two similar tasks, is able to outperform two single-task, individually trained algorithms, by more efficiently learning a new, similar task, that none of the three algorithms has encountered before. The second hypothesis is driven by the question of whether the same multi-task deep RL algorithm, trained on two similar tasks and augmented with elastic weight consolidation (EWC), is able to retain similar performance on the new task, as a similar algorithm without EWC, whilst being able to overcome catastrophic forgetting in the two previous tasks. We show that a multi-task Asynchronous Advantage Actor-Critic (GA3C) algorithm, trained on Space Invaders and Demon Attack, is in fact able to outperform two single-tasks GA3C versions, trained individually for each single-task, when evaluated on a new, third task, namely, Phoenix. We also show that, when training two trained multi-task GA3C algorithms on the third task, if one is augmented with EWC, it is not only able to achieve similar performance on the new task, but also capable of overcoming a substantial amount of catastrophic forgetting on the two previous tasks.