 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Feature Scaling In Machine Learning: Effects on Regression and Classification Tasks
Jun 11, 2025This research addresses the critical lack of comprehensive studies on feature scaling by systematically evaluating 12 scaling techniques - including several less common transformations - across 14 different Machine Learning algorithms and 16 datasets for classification and regression tasks. We meticulously analyzed impacts on predictive performance (using metrics such as accuracy, MAE, MSE, and $R^2$) and computational costs (training time, inference time, and memory usage). Key findings reveal that while ensemble methods (such as Random Forest and gradient boosting models like XGBoost, CatBoost and LightGBM) demonstrate robust performance largely independent of scaling, other widely used models such as Logistic Regression, SVMs, TabNet, and MLPs show significant performance variations highly dependent on the chosen scaler. This extensive empirical analysis, with all source code, experimental results, and model parameters made publicly available to ensure complete transparency and reproducibility, offers model-specific crucial guidance to practitioners on the need for an optimal selection of feature scaling techniques.
A Leaf-Level Dataset for Soybean-Cotton Detection and Segmentation
Mar 03, 2025


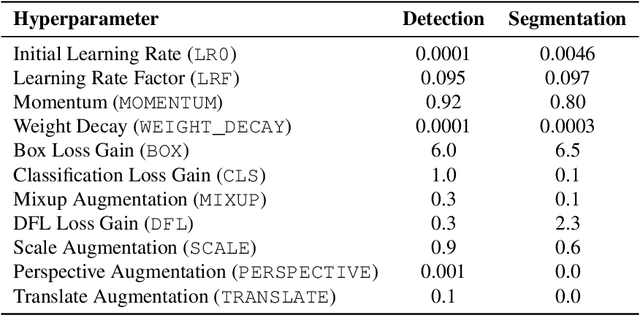
Soybean and cotton are major drivers of many countries' agricultural sectors, offering substantial economic returns but also facing persistent challenges from volunteer plants and weeds that hamper sustainable management. Effectively controlling volunteer plants and weeds demands advanced recognition strategies that can identify these amidst complex crop canopies. While deep learning methods have demonstrated promising results for leaf-level detection and segmentation, existing datasets often fail to capture the complexity of real-world agricultural fields. To address this, we collected 640 high-resolution images from a commercial farm spanning multiple growth stages, weed pressures, and lighting variations. Each image is annotated at the leaf-instance level, with 7,221 soybean and 5,190 cotton leaves labeled via bounding boxes and segmentation masks, capturing overlapping foliage, small leaf size, and morphological similarities. We validate this dataset using YOLOv11, demonstrating state-of-the-art performance in accurately identifying and segmenting overlapping foliage. Our publicly available dataset supports advanced applications such as selective herbicide spraying and pest monitoring and can foster more robust, data-driven strategies for soybean-cotton management.
Breast Cancer Classification Using Gradient Boosting Algorithms Focusing on Reducing the False Negative and SHAP for Explainability
Mar 14, 2024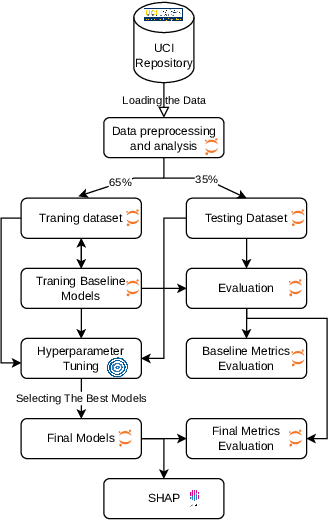
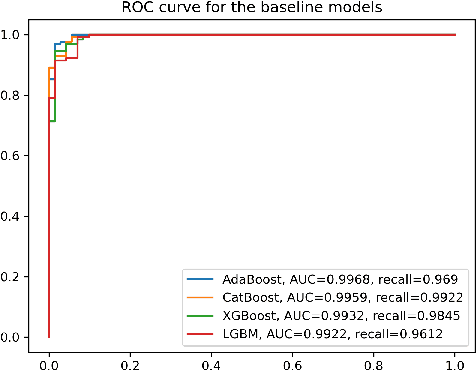
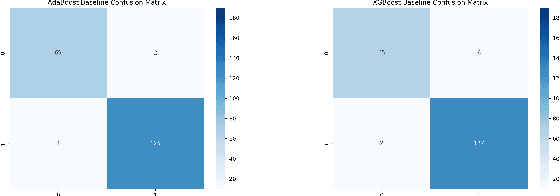
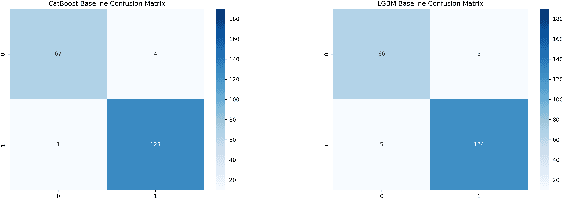
Cancer is one of the diseases that kill the most women in the world, with breast cancer being responsible for the highest number of cancer cases and consequently deaths. However, it can be prevented by early detection and, consequently, early treatment. Any development for detection or perdition this kind of cancer is important for a better healthy life. Many studies focus on a model with high accuracy in cancer prediction, but sometimes accuracy alone may not always be a reliable metric. This study implies an investigative approach to studying the performance of different machine learning algorithms based on boosting to predict breast cancer focusing on the recall metric. Boosting machine learning algorithms has been proven to be an effective tool for detecting medical diseases. The dataset of the University of California, Irvine (UCI) repository has been utilized to train and test the model classifier that contains their attributes. The main objective of this study is to use state-of-the-art boosting algorithms such as AdaBoost, XGBoost, CatBoost and LightGBM to predict and diagnose breast cancer and to find the most effective metric regarding recall, ROC-AUC, and confusion matrix. Furthermore, our study is the first to use these four boosting algorithms with Optuna, a library for hyperparameter optimization, and the SHAP method to improve the interpretability of our model, which can be used as a support to identify and predict breast cancer. We were able to improve AUC or recall for all the models and reduce the False Negative for AdaBoost and LigthGBM the final AUC were more than 99.41\% for all models.