 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Audio to Symbolic Encoding
Feb 26, 2023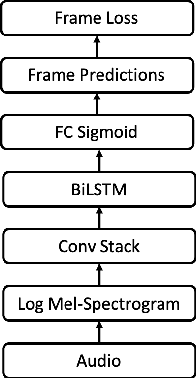
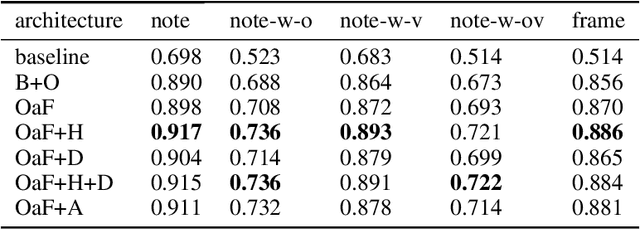

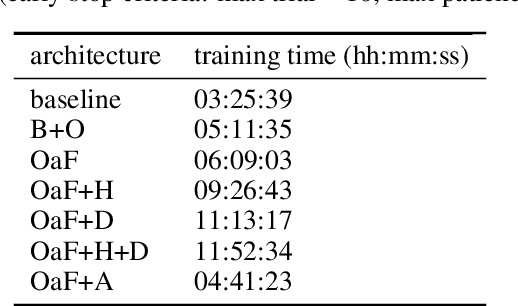
Automatic music transcription (AMT) aims to convert raw audio to symbolic music representation. As a fundamental problem of music information retrieval (MIR), AMT is considered a difficult task even for trained human experts due to overlap of multiple harmonics in the acoustic signal. On the other hand, speech recognition, as one of the most popular tasks in natural language processing, aims to translate human spoken language to texts. Based on the similar nature of AMT and speech recognition (as they both deal with tasks of translating audio signal to symbolic encoding), this paper investigated whether a generic neural network architecture could possibly work on both tasks. In this paper, we introduced our new neural network architecture built on top of the current state-of-the-art Onsets and Frames, and compared the performances of its multiple variations on AMT task. We also tested our architecture with the task of speech recognition. For AMT, our models were able to produce better results compared to the model trained using the state-of-art architecture; however, although similar architecture was able to be trained on the speech recognition task, it did not generate very ideal result compared to other task-specific models.