 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-efficient Dysarthric Speech Recognition Using Adapter Fusion and Householder Transformation
Jun 12, 2023In dysarthric speech recognition, data scarcity and the vast diversity between dysarthric speakers pose significant challenges. While finetuning has been a popular solution, it can lead to overfitting and low parameter efficiency. Adapter modules offer a better solution, with their small size and easy applicability. Additionally, Adapter Fusion can facilitate knowledge transfer from multiple learned adapters, but may employ more parameters. In this work, we apply Adapter Fusion for target speaker adaptation and speech recognition, achieving acceptable accuracy with significantly fewer speaker-specific trainable parameters than classical finetuning methods. We further improve the parameter efficiency of the fusion layer by reducing the size of query and key layers and using Householder transformation to reparameterize the value linear layer. Our proposed fusion layer achieves comparable recognition results to the original method with only one third of the parameters.
Weak-Supervised Dysarthria-invariant Features for Spoken Language Understanding using an FHVAE and Adversarial Training
Oct 24, 2022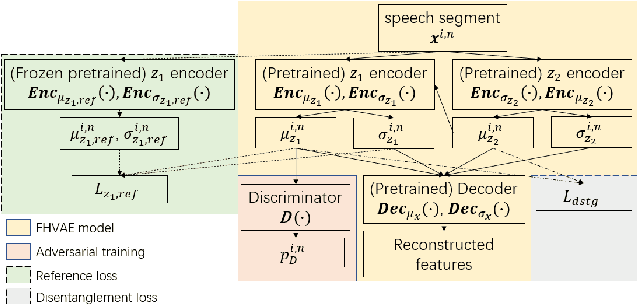
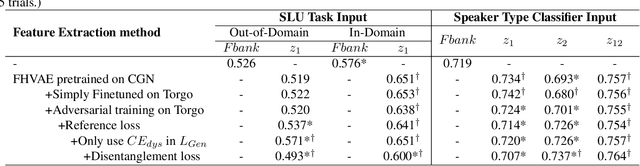
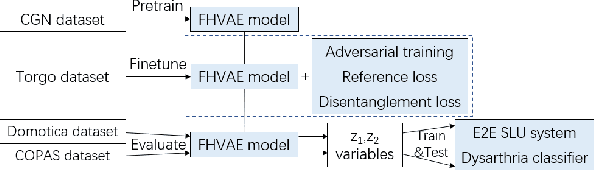
The scarcity of training data and the large speaker variation in dysarthric speech lead to poor accuracy and poor speaker generalization of spoken language understanding systems for dysarthric speech. Through work on the speech features, we focus on improving the model generalization ability with limited dysarthric data. Factorized Hierarchical Variational Auto-Encoders (FHVAE) trained unsupervisedly have shown their advantage in disentangling content and speaker representations. Earlier work showed that the dysarthria shows in both feature vectors. Here, we add adversarial training to bridge the gap between the control and dysarthric speech data domains. We extract dysarthric and speaker invariant features using weak supervision. The extracted features are evaluated on a Spoken Language Understanding task and yield a higher accuracy on unseen speakers with more severe dysarthria compared to features from the basic FHVAE model or plain filterbanks.
Speech Disorder Classification Using Extended Factorized Hierarchical Variational Auto-encoders
Jun 14, 2021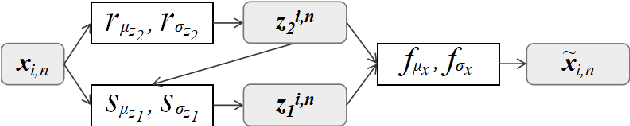

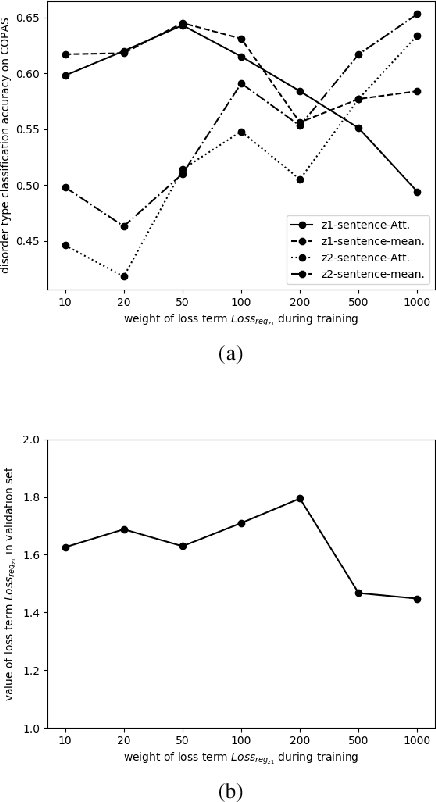
Objective speech disorder classification for speakers with communication difficulty is desirable for diagnosis and administering therapy. With the current state of speech technology, it is evident to propose neural networks for this application. But neural network model training is hampered by a lack of labeled disordered speech data. In this research, we apply an extended version of Factorized Hierarchical Variational Auto-encoders (FHVAE) for representation learning on disordered speech. The FHVAE model extracts both content-related and sequence-related latent variables from speech data, and we utilize the extracted variables to explore how disorder type information is represented in the latent variables. For better classification performance, the latent variables are aggregated at the word and sentence level. We show that an extension of the FHVAE model succeeds in the better disentanglement of the content-related and sequence-related related representations, but both representations are still required for best results on disorder type classification.