 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Textual Association with Hardest and Semi-Hard Negative Pairs Mining for Person Search
Dec 06, 2019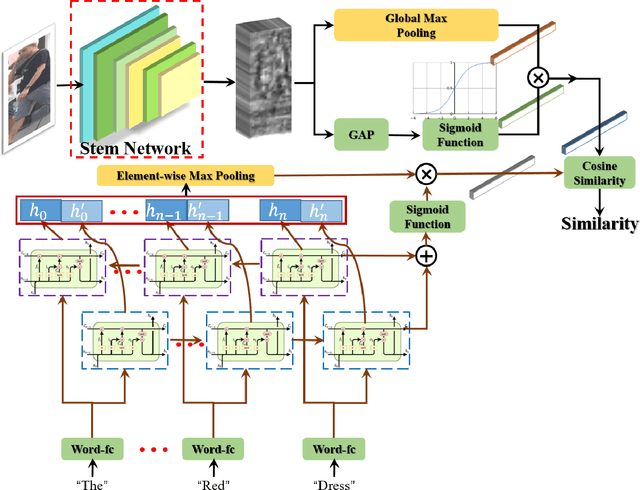
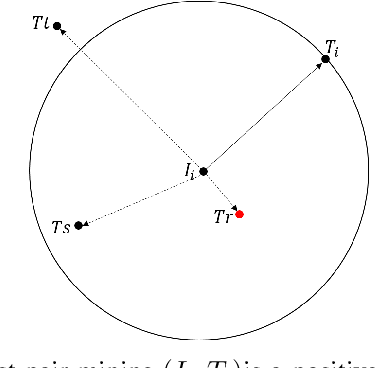
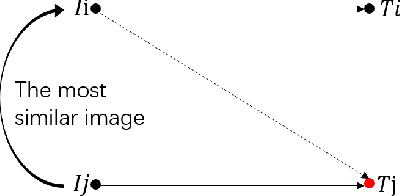
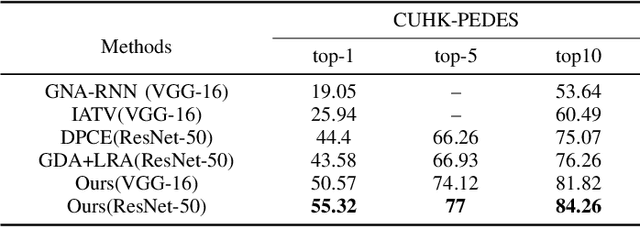
Searching persons in large-scale image databases with the query of natural language description is a more practical important applications in video surveillance. Intuitively, for person search, the core issue should be visual-textual association, which is still an extremely challenging task, due to the contradiction between the high abstraction of textual description and the intuitive expression of visual images. However, for this task, while positive image-text pairs are always well provided, most existing methods doesn't tackle this problem effectively by mining more reasonable negative pairs. In this paper, we proposed a novel visual-textual association approach with visual and textual attention, and cross-modality hardest and semi-hard negative pair mining. In order to evaluate the effectiveness and feasibility of the proposed approach, we conduct extensive experiments on typical person search datasdet: CUHK-PEDES, in which our approach achieves the top1 score of 55.32% as a new state-of-the-art. Besides, we also evaluate the semi-hard pair mining approach in COCO caption dataset, and validate the effectiveness and complementarity of the methods.