 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical Metadata Representation for Customized Text Classification
Feb 14, 2019The performance of text classification has improved tremendously using intelligently engineered neural-based models, especially those injecting categorical metadata as additional information, e.g., using user/product information for sentiment classification. These information have been used to modify parts of the model (e.g., word embeddings, attention mechanisms) such that results can be customized according to the metadata. We observe that current representation methods for categorical metadata, which are devised for human consumption, are not as effective as claimed in popular classification methods, outperformed even by simple concatenation of categorical features in the final layer of the sentence encoder. We conjecture that categorical features are harder to represent for machine use, as available context only indirectly describes the category, and even such context is often scarce (for tail category). To this end, we propose to use basis vectors to effectively incorporate categorical metadata on various parts of a neural-based model. This additionally decreases the number of parameters dramatically, especially when the number of categorical features is large. Extensive experiments on various datasets with different properties are performed and show that through our method, we can represent categorical metadata more effectively to customize parts of the model, including unexplored ones, and increase the performance of the model greatly.
Cold-Start Aware User and Product Attention for Sentiment Classification
Jun 14, 2018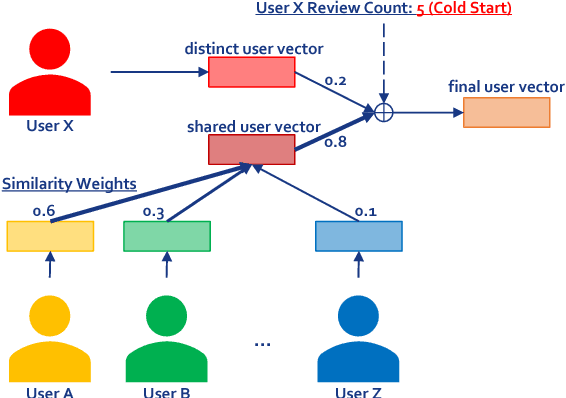
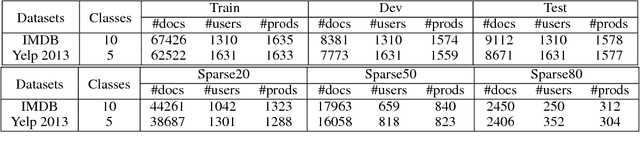
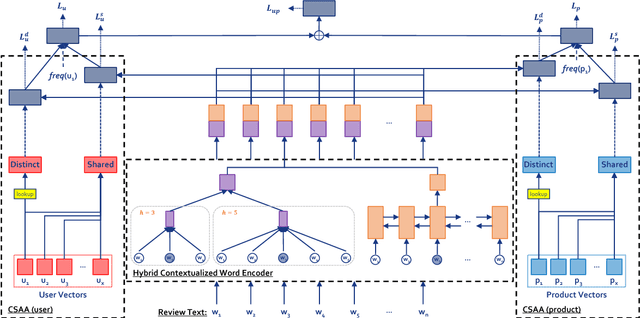
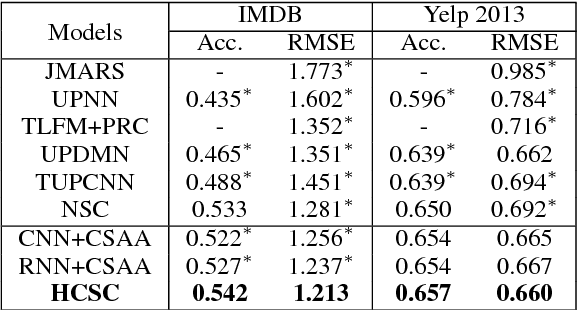
The use of user/product information in sentiment analysis is important, especially for cold-start users/products, whose number of reviews are very limited. However, current models do not deal with the cold-start problem which is typical in review websites. In this paper, we present Hybrid Contextualized Sentiment Classifier (HCSC), which contains two modules: (1) a fast word encoder that returns word vectors embedded with short and long range dependency features; and (2) Cold-Start Aware Attention (CSAA), an attention mechanism that considers the existence of cold-start problem when attentively pooling the encoded word vectors. HCSC introduces shared vectors that are constructed from similar users/products, and are used when the original distinct vectors do not have sufficient information (i.e. cold-start). This is decided by a frequency-guided selective gate vector. Our experiments show that in terms of RMSE, HCSC performs significantly better when compared with on famous datasets, despite having less complexity, and thus can be trained much faster. More importantly, our model performs significantly better than previous models when the training data is sparse and has cold-start problems.