 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Swap-Adversarial Framework for Improving Domain Generalization in Electroencephalography-Based Parkinson's Disease Prediction
Feb 11, 2026Electroencephalography (ECoG) offers a promising alternative to conventional electrocorticography (EEG) for the early prediction of Parkinson's disease (PD), providing higher spatial resolution and a broader frequency range. However, reproducible comparisons has been limited by ethical constraints in human studies and the lack of open benchmark datasets. To address this gap, we introduce a new dataset, the first reproducible benchmark for PD prediction. It is constructed from long-term ECoG recordings of 6-hydroxydopamine (6-OHDA)-induced rat models and annotated with neural responses measured before and after electrical stimulation. In addition, we propose a Swap-Adversarial Framework (SAF) that mitigates high inter-subject variability and the high-dimensional low-sample-size (HDLSS) problem in ECoG data, while achieving robust domain generalization across ECoG and EEG-based Brain-Computer Interface (BCI) datasets. The framework integrates (1) robust preprocessing, (2) Inter-Subject Balanced Channel Swap (ISBCS) for cross-subject augmentation, and (3) domain-adversarial training to suppress subject-specific bias. ISBCS randomly swaps channels between subjects to reduce inter-subject variability, and domain-adversarial training jointly encourages the model to learn task-relevant shared features. We validated the effectiveness of the proposed method through extensive experiments under cross-subject, cross-session, and cross-dataset settings. Our method consistently outperformed all baselines across all settings, showing the most significant improvements in highly variable environments. Furthermore, the proposed method achieved superior cross-dataset performance between public EEG benchmarks, demonstrating strong generalization capability not only within ECoG but to EEG data. The new dataset and source code will be made publicly available upon publication.
ContrastCAD: Contrastive Learning-based Representation Learning for Computer-Aided Design Models
Apr 02, 2024



The success of Transformer-based models has encouraged many researchers to learn CAD models using sequence-based approaches. However, learning CAD models is still a challenge, because they can be represented as complex shapes with long construction sequences. Furthermore, the same CAD model can be expressed using different CAD construction sequences. We propose a novel contrastive learning-based approach, named ContrastCAD, that effectively captures semantic information within the construction sequences of the CAD model. ContrastCAD generates augmented views using dropout techniques without altering the shape of the CAD model. We also propose a new CAD data augmentation method, called a Random Replace and Extrude (RRE) method, to enhance the learning performance of the model when training an imbalanced training CAD dataset. Experimental results show that the proposed RRE augmentation method significantly enhances the learning performance of Transformer-based autoencoders, even for complex CAD models having very long construction sequences. The proposed ContrastCAD model is shown to be robust to permutation changes of construction sequences and performs better representation learning by generating representation spaces where similar CAD models are more closely clustered. Our codes are available at https://github.com/cm8908/ContrastCAD.
Mol-AIR: Molecular Reinforcement Learning with Adaptive Intrinsic Rewards for Goal-directed Molecular Generation
Mar 29, 2024



Optimizing techniques for discovering molecular structures with desired properties is crucial in artificial intelligence(AI)-based drug discovery. Combining deep generative models with reinforcement learning has emerged as an effective strategy for generating molecules with specific properties. Despite its potential, this approach is ineffective in exploring the vast chemical space and optimizing particular chemical properties. To overcome these limitations, we present Mol-AIR, a reinforcement learning-based framework using adaptive intrinsic rewards for effective goal-directed molecular generation. Mol-AIR leverages the strengths of both history-based and learning-based intrinsic rewards by exploiting random distillation network and counting-based strategies. In benchmark tests, Mol-AIR demonstrates superior performance over existing approaches in generating molecules with desired properties without any prior knowledge, including penalized LogP, QED, and celecoxib similarity. We believe that Mol-AIR represents a significant advancement in drug discovery, offering a more efficient path to discovering novel therapeutics.
A Lightweight CNN-Transformer Model for Learning Traveling Salesman Problems
May 03, 2023Transformer-based models show state-of-the-art performance even for large-scale Traveling Salesman Problems (TSPs). However, they are based on fully-connected attention models and suffer from large computational complexity and GPU memory usage. We propose a lightweight CNN-Transformer model based on a CNN embedding layer and partial self-attention. Our CNN-Transformer model is able to better learn spatial features from input data using a CNN embedding layer compared with the standard Transformer models. It also removes considerable redundancy in fully connected attention models using the proposed partial self-attention. Experiments show that the proposed model outperforms other state-of-the-art Transformer-based models in terms of TSP solution quality, GPU memory usage, and inference time. Our model consumes approximately 20% less GPU memory usage and has 45% faster inference time compared with other state-of-the-art Transformer-based models. Our code is publicly available at https://github.com/cm8908/CNN_Transformer3
Learning Delaunay Triangulation using Self-attention and Domain Knowledge
Jul 05, 2021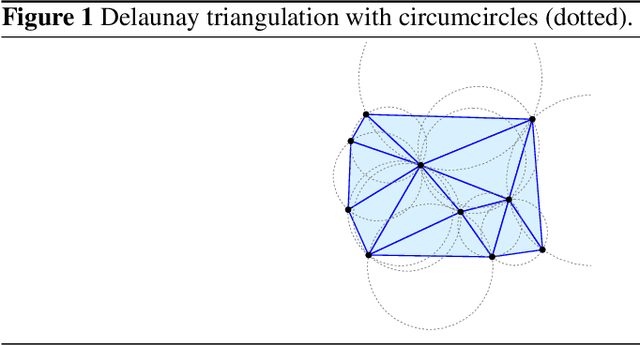
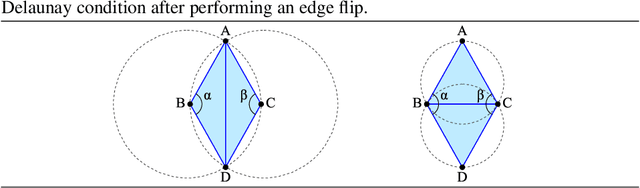
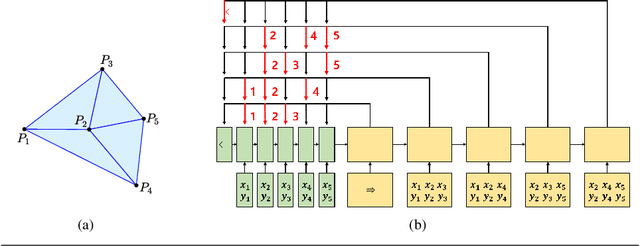
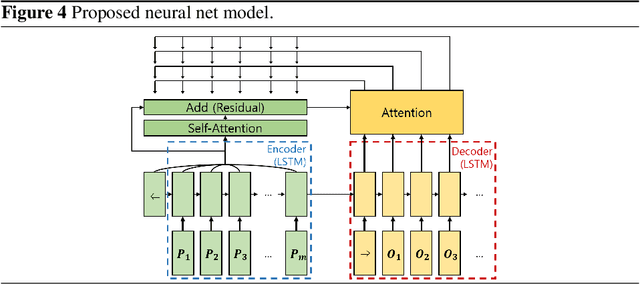
Delaunay triangulation is a well-known geometric combinatorial optimization problem with various applications. Many algorithms can generate Delaunay triangulation given an input point set, but most are nontrivial algorithms requiring an understanding of geometry or the performance of additional geometric operations, such as the edge flip. Deep learning has been used to solve various combinatorial optimization problems; however, generating Delaunay triangulation based on deep learning remains a difficult problem, and very few research has been conducted due to its complexity. In this paper, we propose a novel deep-learning-based approach for learning Delaunay triangulation using a new attention mechanism based on self-attention and domain knowledge. The proposed model is designed such that the model efficiently learns point-to-point relationships using self-attention in the encoder. In the decoder, a new attention score function using domain knowledge is proposed to provide a high penalty when the geometric requirement is not satisfied. The strength of the proposed attention score function lies in its ability to extend its application to solving other combinatorial optimization problems involving geometry. When the proposed neural net model is well trained, it is simple and efficient because it automatically predicts the Delaunay triangulation for an input point set without requiring any additional geometric operations. We conduct experiments to demonstrate the effectiveness of the proposed model and conclude that it exhibits better performance compared with other deep-learning-based approaches.