 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-Enhanced Retrieval Tool for Homework Plagiarism Detection System
Apr 01, 2024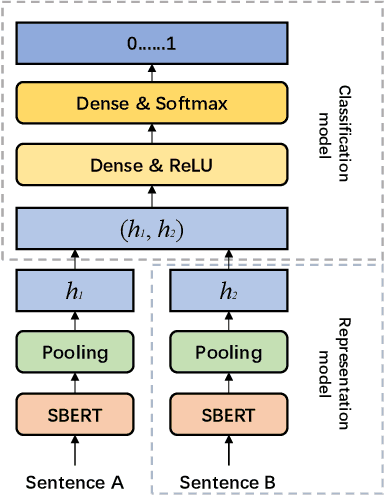

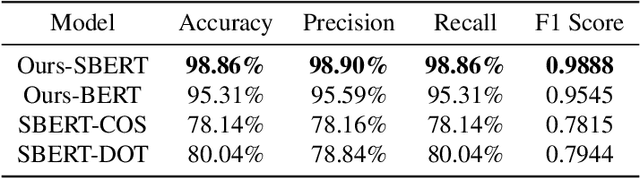

Text plagiarism detection task is a common natural language processing task that aims to detect whether a given text contains plagiarism or copying from other texts. In existing research, detection of high level plagiarism is still a challenge due to the lack of high quality datasets. In this paper, we propose a plagiarized text data generation method based on GPT-3.5, which produces 32,927 pairs of text plagiarism detection datasets covering a wide range of plagiarism methods, bridging the gap in this part of research. Meanwhile, we propose a plagiarism identification method based on Faiss with BERT with high efficiency and high accuracy. Our experiments show that the performance of this model outperforms other models in several metrics, including 98.86\%, 98.90%, 98.86%, and 0.9888 for Accuracy, Precision, Recall, and F1 Score, respectively. At the end, we also provide a user-friendly demo platform that allows users to upload a text library and intuitively participate in the plagiarism analysis.