 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELEGANT: Exchanging Latent Encodings with GAN for Transferring Multiple Face Attributes
Jul 25, 2018
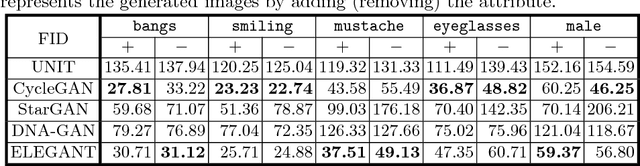


Recent studies on face attribute transfer have achieved great success. A lot of models are able to transfer face attributes with an input image. However, they suffer from three limitations: (1) incapability of generating image by exemplars; (2) being unable to transfer multiple face attributes simultaneously; (3) low quality of generated images, such as low-resolution or artifacts. To address these limitations, we propose a novel model which receives two images of opposite attributes as inputs. Our model can transfer exactly the same type of attributes from one image to another by exchanging certain part of their encodings. All the attributes are encoded in a disentangled manner in the latent space, which enables us to manipulate several attributes simultaneously. Besides, our model learns the residual images so as to facilitate training on higher resolution images. With the help of multi-scale discriminators for adversarial training, it can even generate high-quality images with finer details and less artifacts. We demonstrate the effectiveness of our model on overcoming the above three limitations by comparing with other methods on the CelebA face database. A pytorch implementation is available at https://github.com/Prinsphield/ELEGANT.
* Github: https://github.com/Prinsphield/ELEGANT
DNA-GAN: Learning Disentangled Representations from Multi-Attribute Images
Mar 28, 2018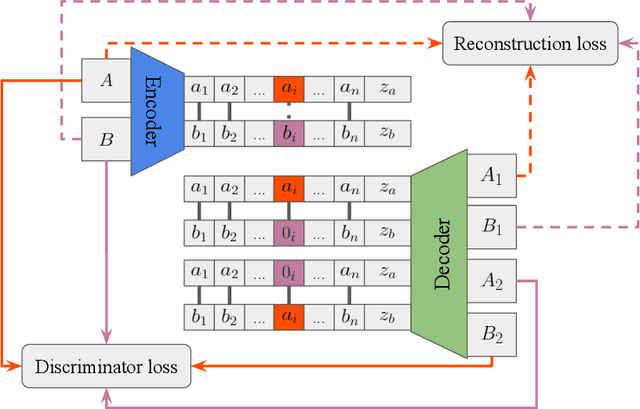



Disentangling factors of variation has become a very challenging problem on representation learning. Existing algorithms suffer from many limitations, such as unpredictable disentangling factors, poor quality of generated images from encodings, lack of identity information, etc. In this paper, we propose a supervised learning model called DNA-GAN which tries to disentangle different factors or attributes of images. The latent representations of images are DNA-like, in which each individual piece (of the encoding) represents an independent factor of the variation. By annihilating the recessive piece and swapping a certain piece of one latent representation with that of the other one, we obtain two different representations which could be decoded into two kinds of images with the existence of the corresponding attribute being changed. In order to obtain realistic images and also disentangled representations, we further introduce the discriminator for adversarial training. Experiments on Multi-PIE and CelebA datasets finally demonstrate that our proposed method is effective for factors disentangling and even overcome certain limitations of the existing methods.